
Identification of Real-Life Mixtures Using Human Biomonitoring Data: A Proof of Concept Study

 , , , , , , ,
, , , , , , ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Selection of Existing HBM Studies
2.2. Data Selection and Preparation
2.3. Characteristics of the Four Existing HBM Datasets
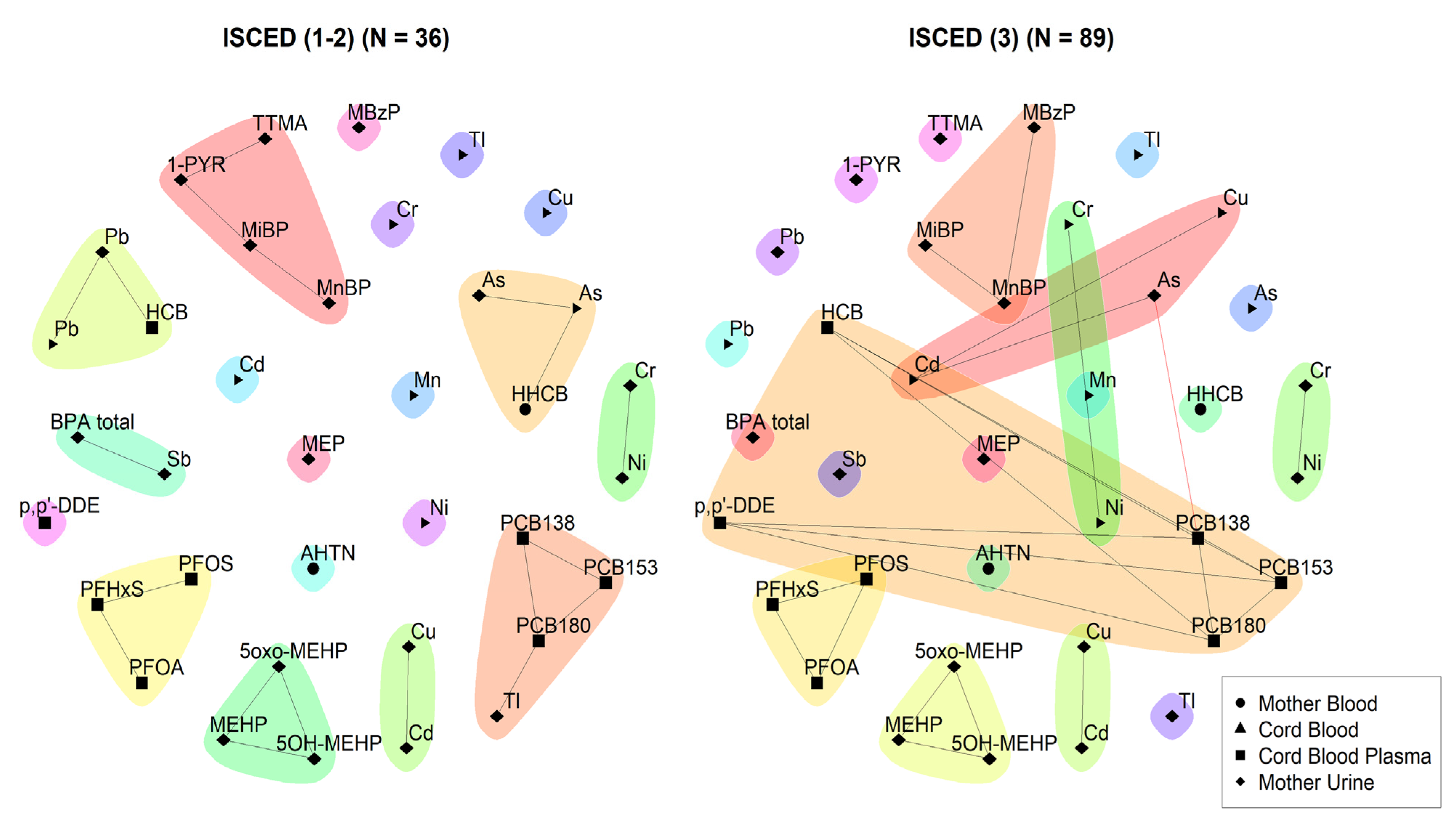
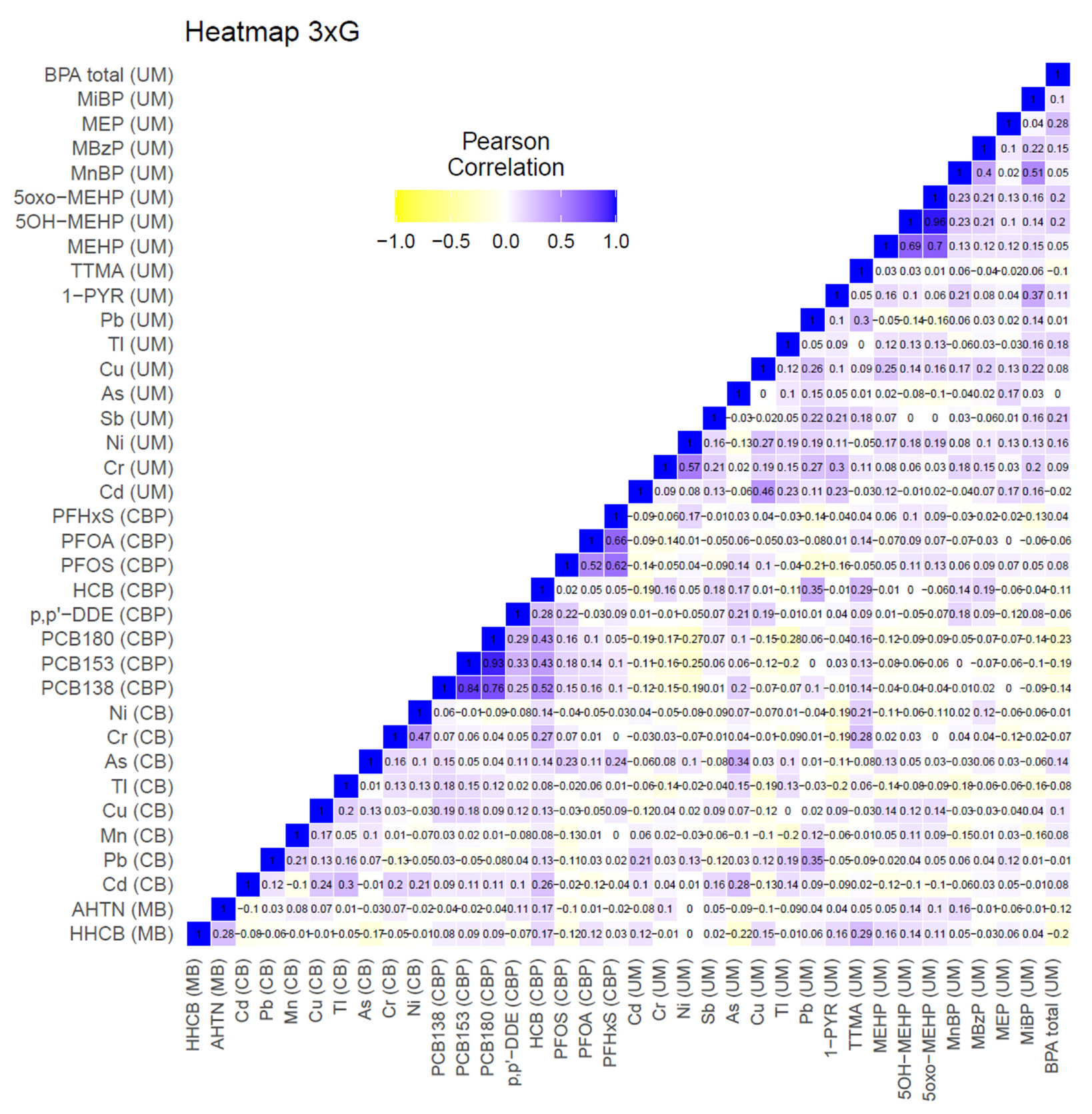
2.3.1. 3xG (Belgium)
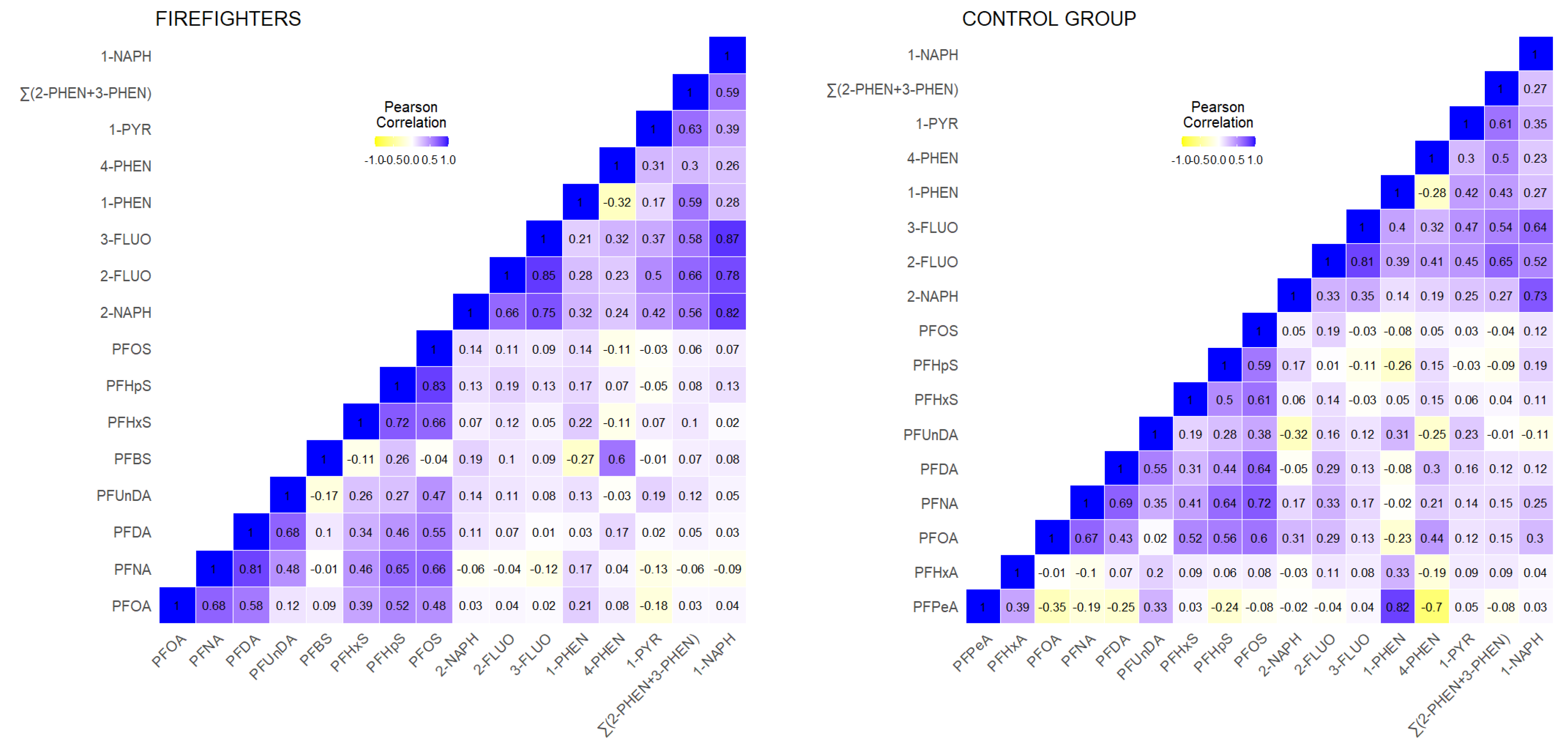
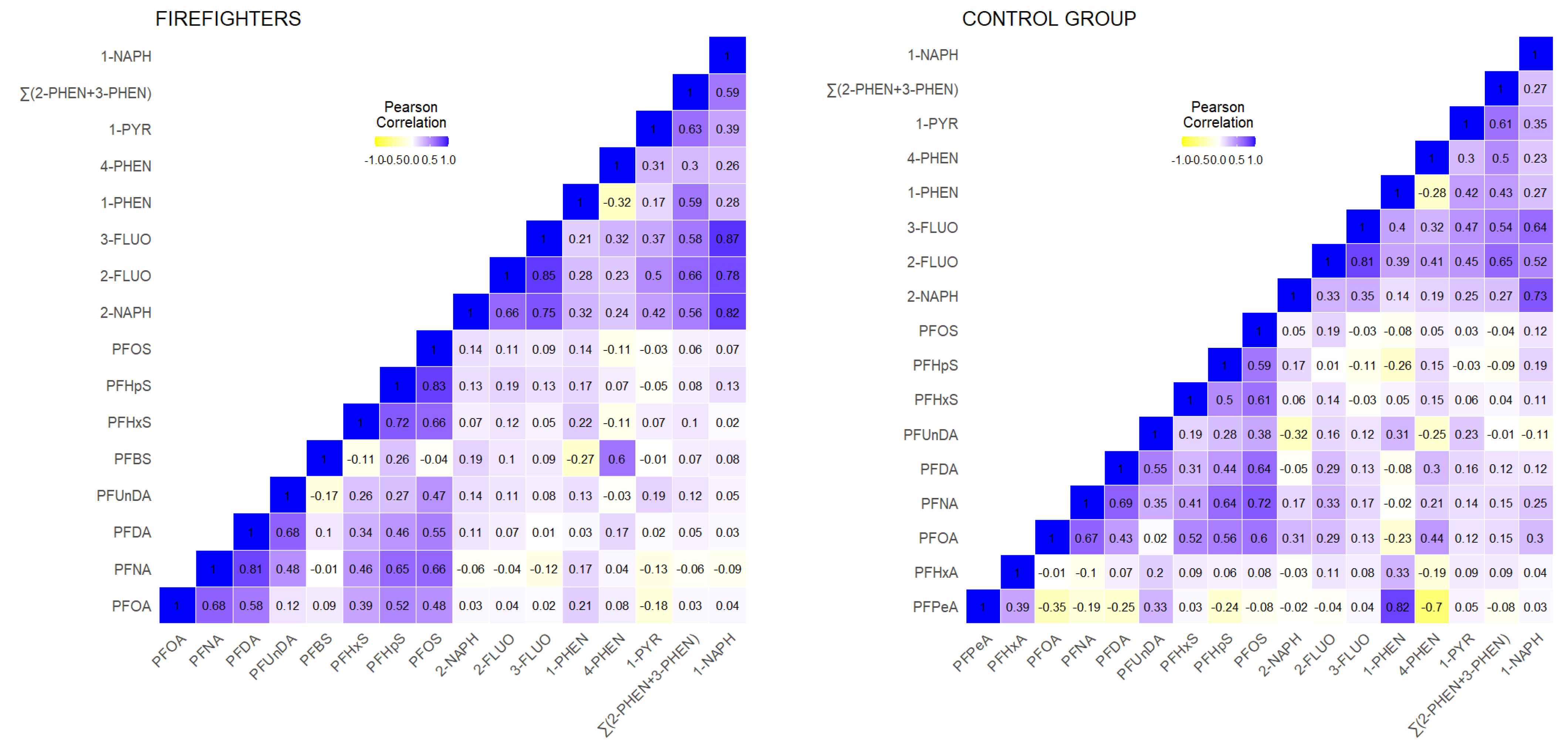
2.3.2. CELSPAC—FIREexpo (Czech Republic)
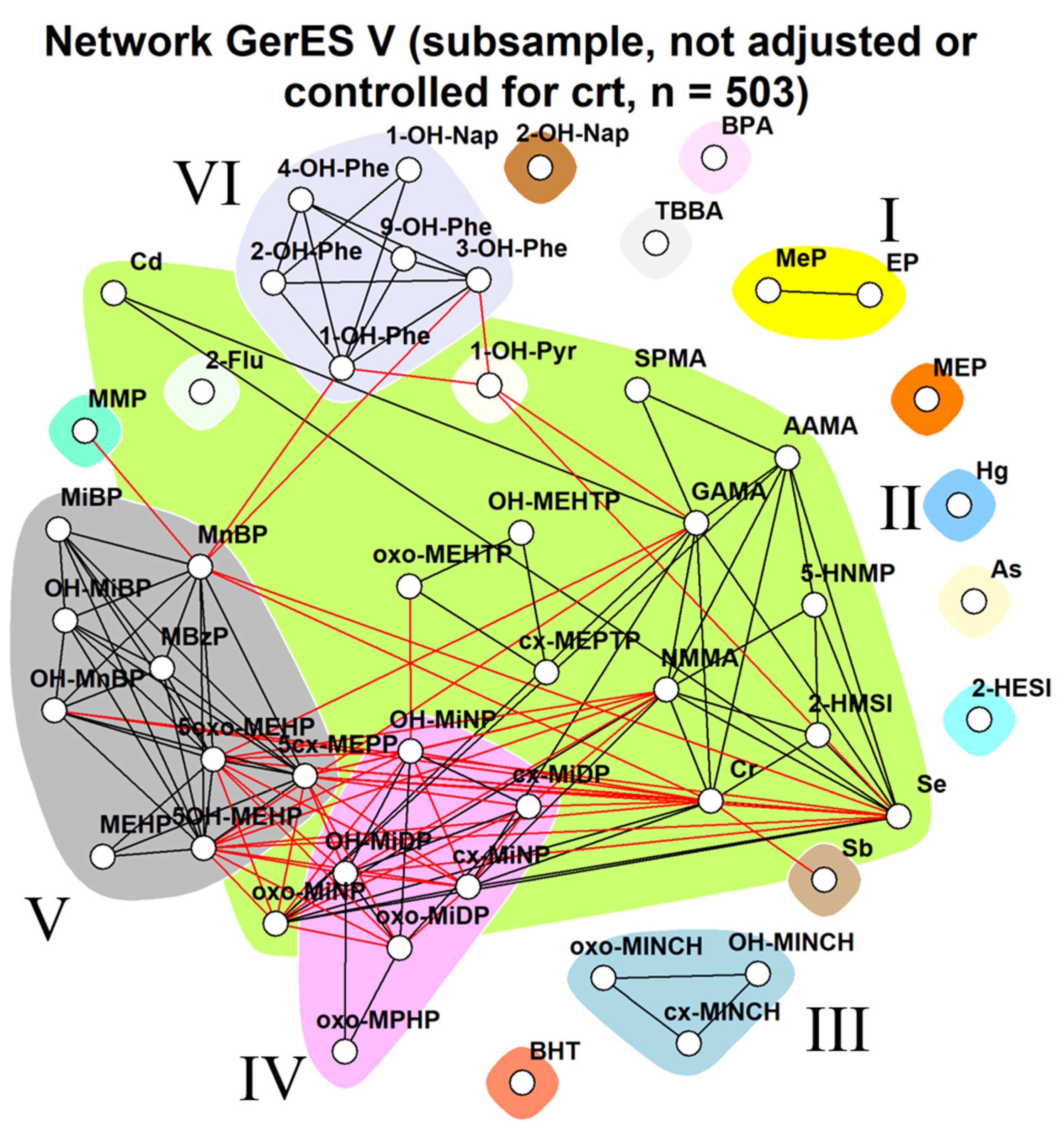
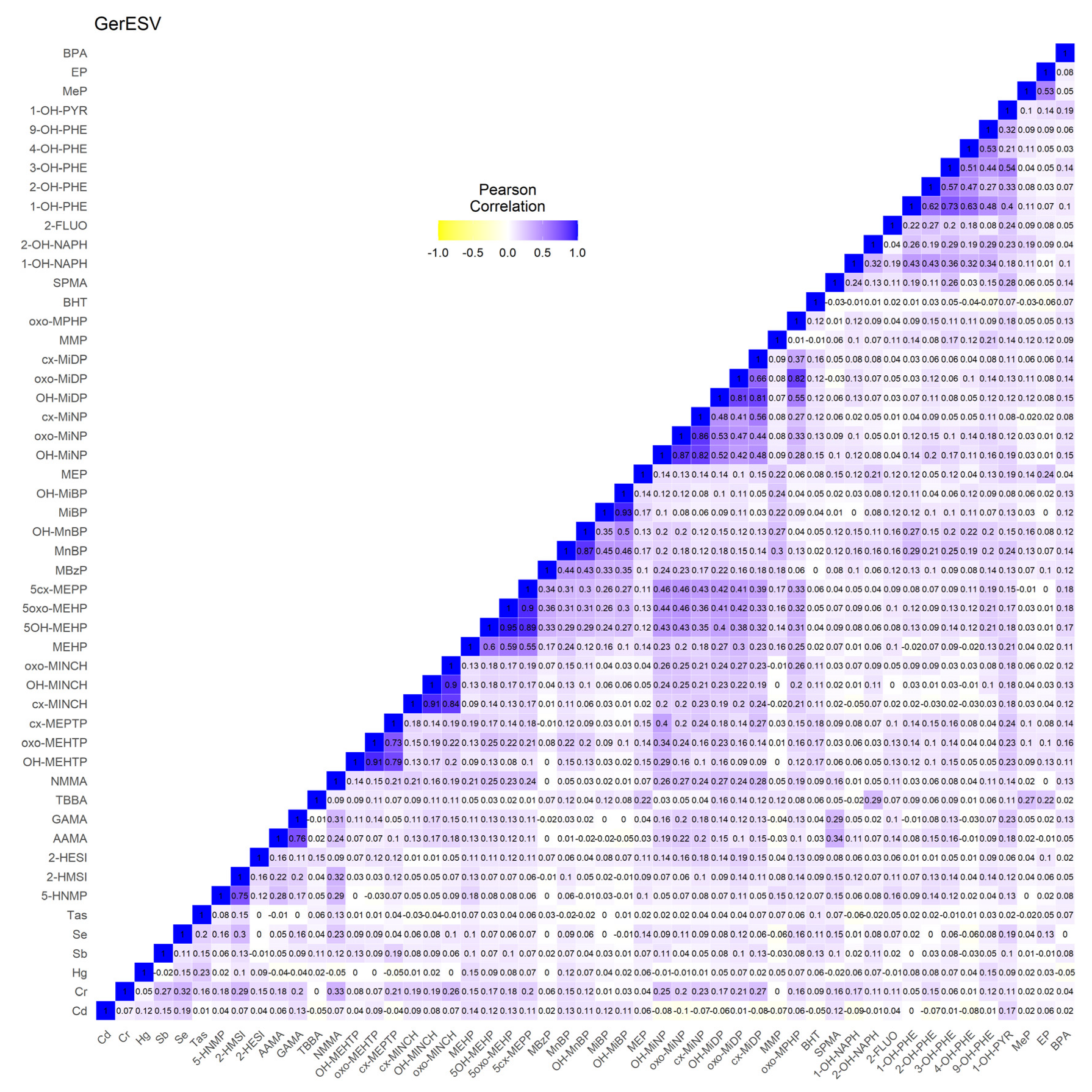
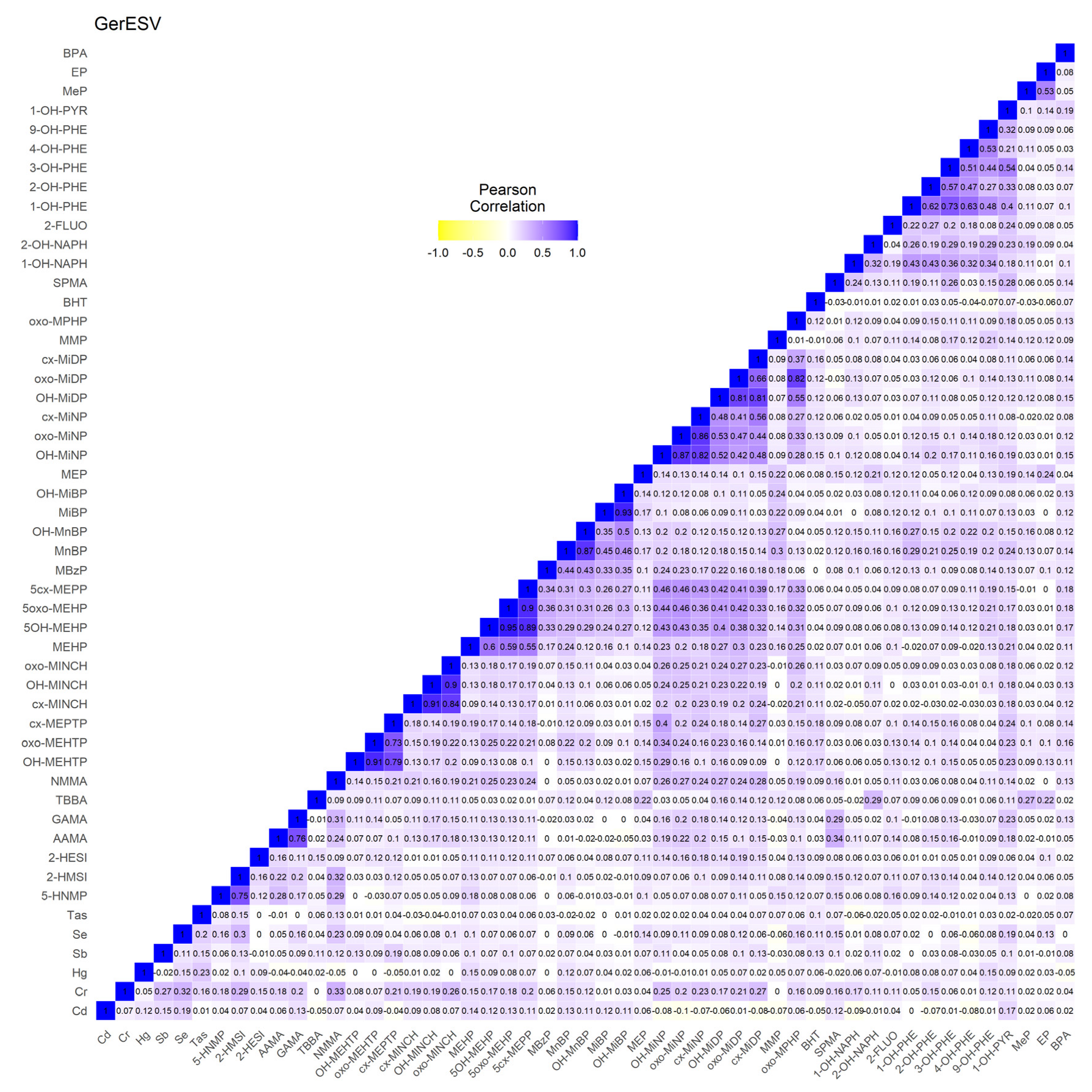
2.3.3. GerES V (Germany)
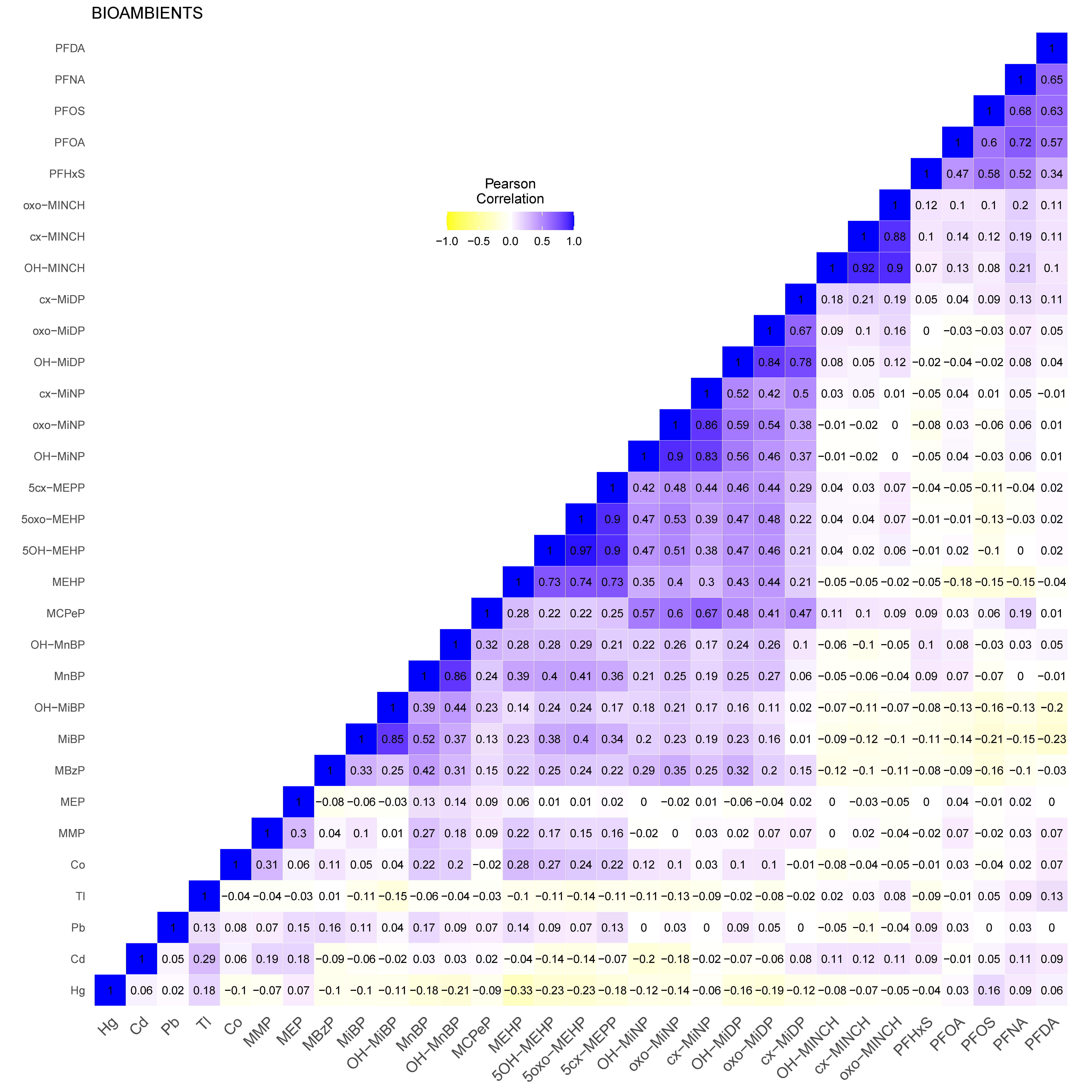
2.3.4. BIOAMBIENT.ES (Spain)
2.4. Statistical Analysis
2.4.1. Descriptive Analysis
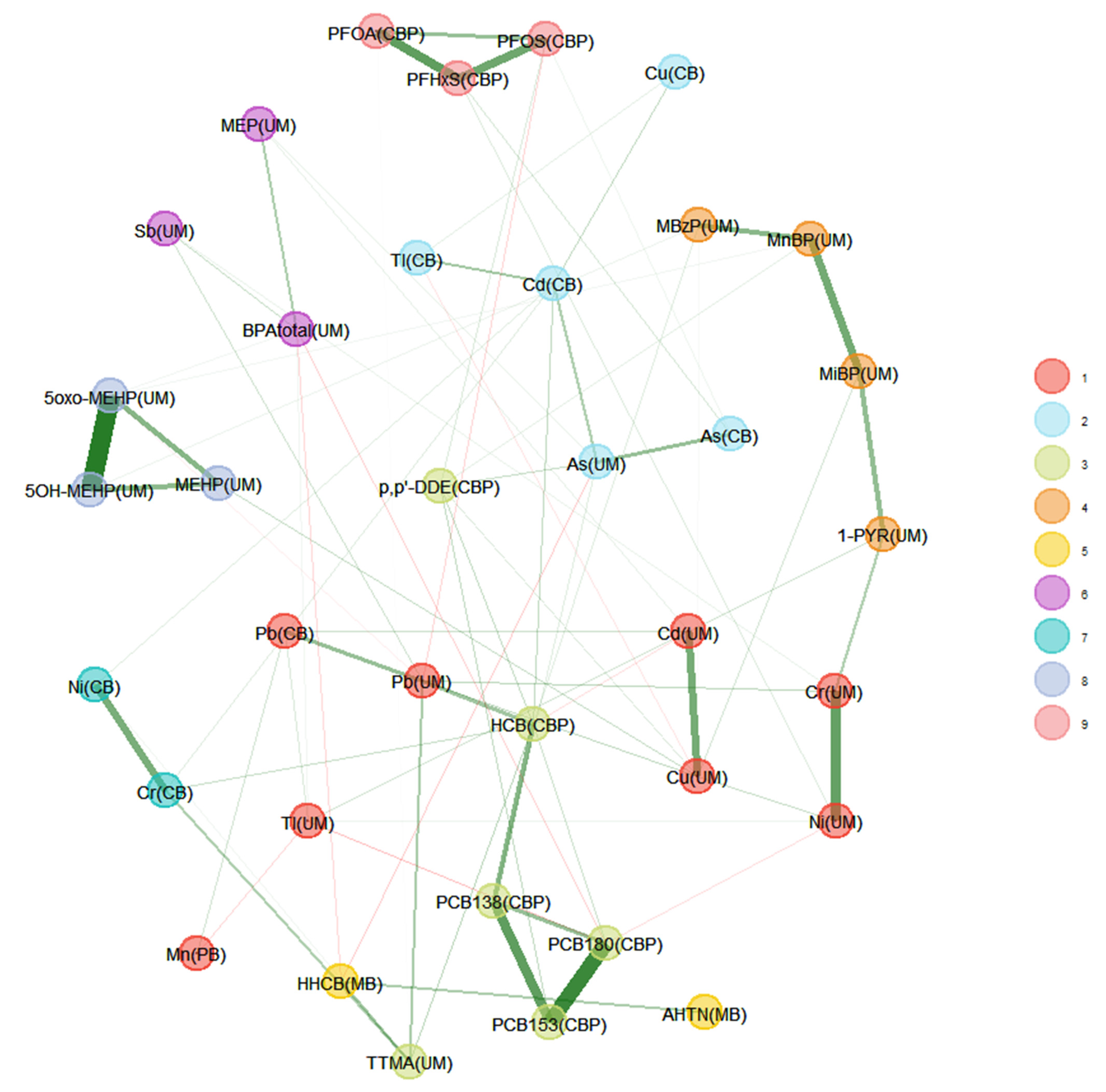
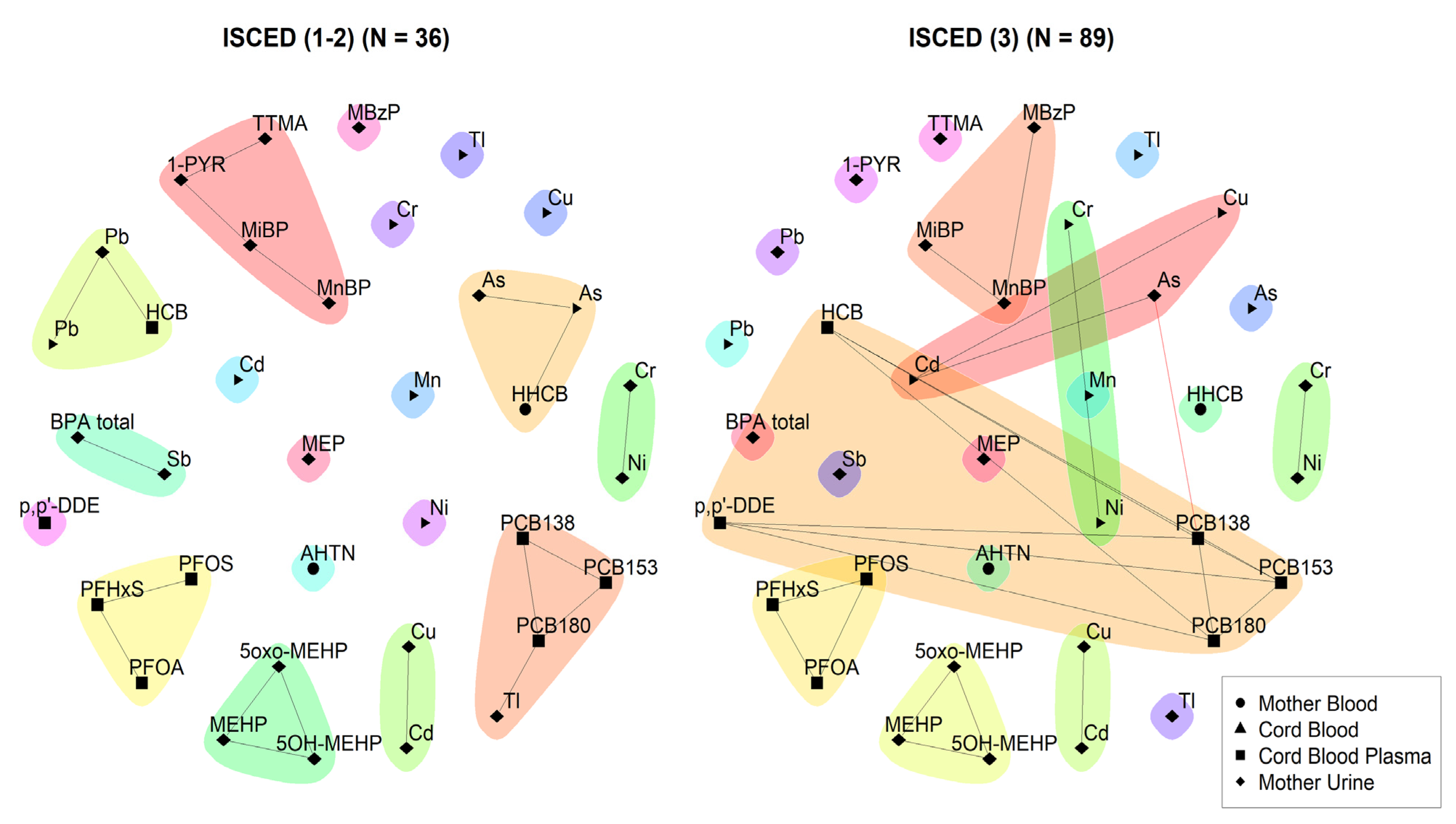
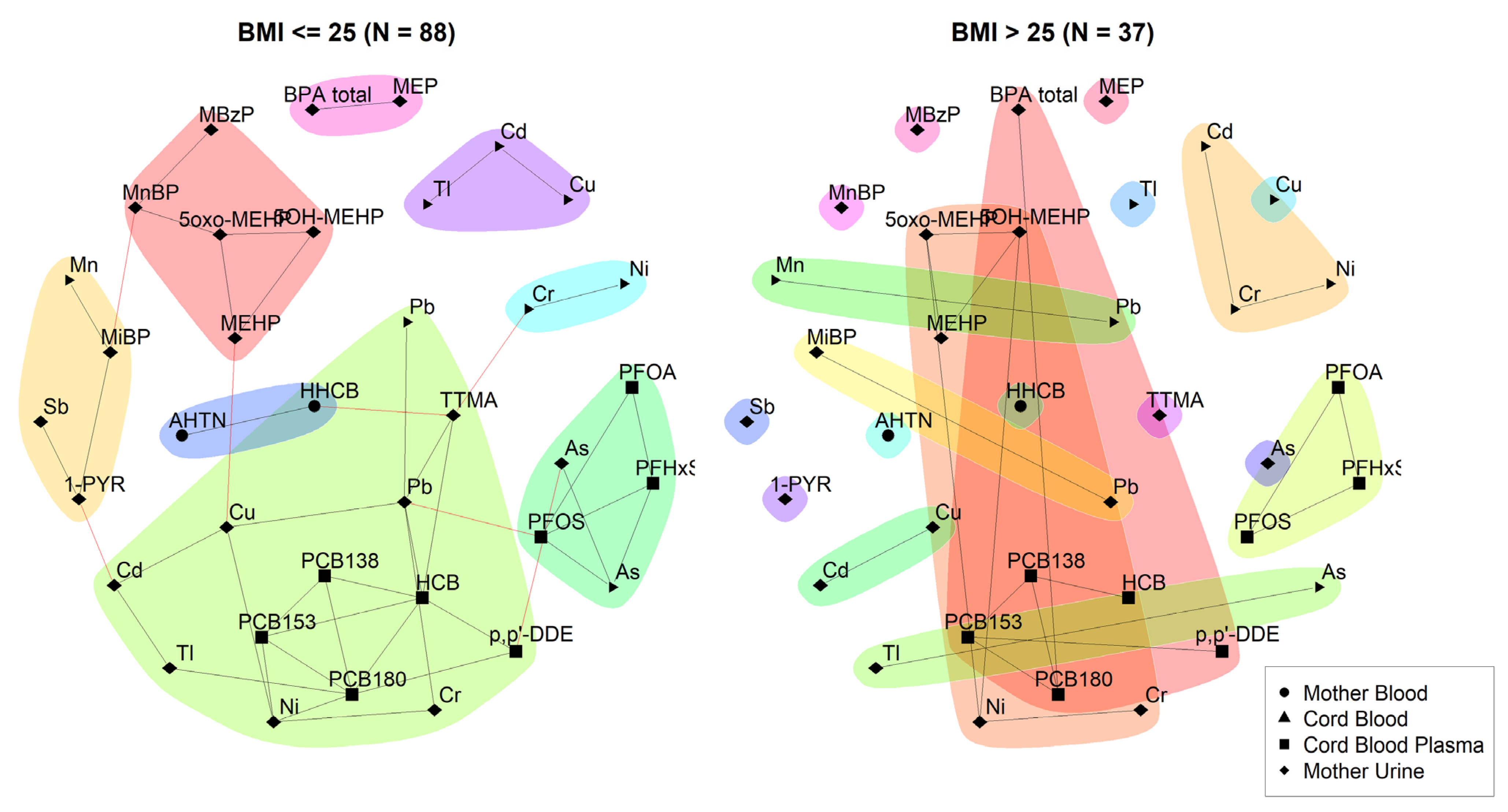
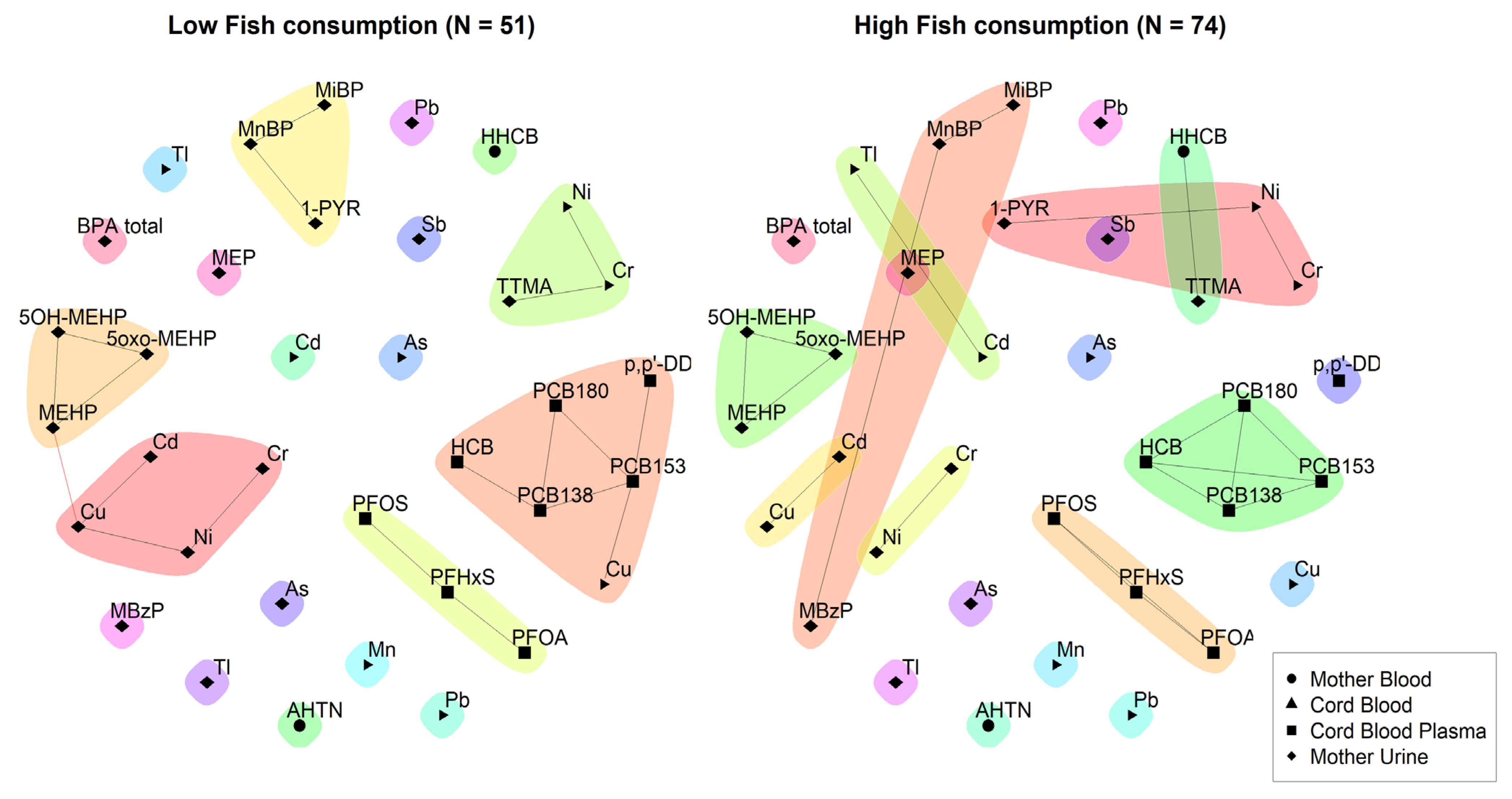
2.4.2. Network Analysis
3. Results
3.1. Descriptive Statistics for the Chemical Substances Included in the Network Analysis
3.1.1. 3xG (Belgium)
3.1.2. CELSPAC—FIREexpo (Czech Republic)
3.1.3. GerES V (Germany)
3.1.4. BIOAMBIENT.ES (Spain)
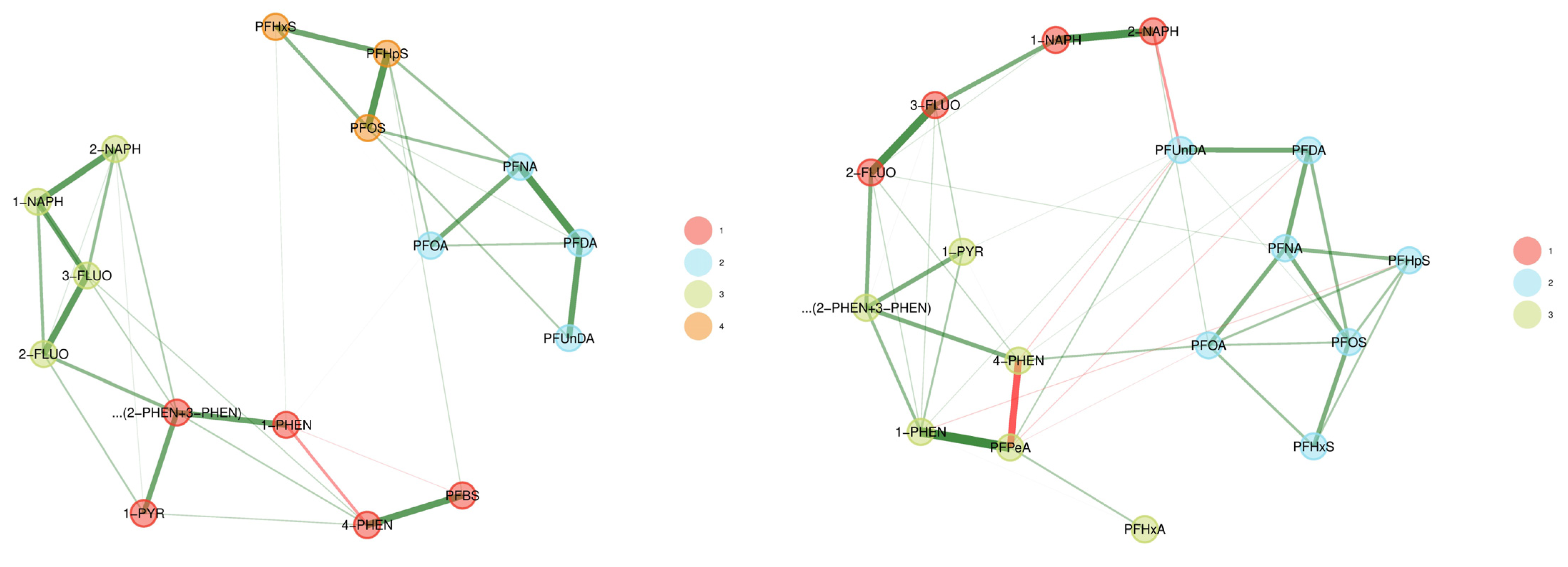
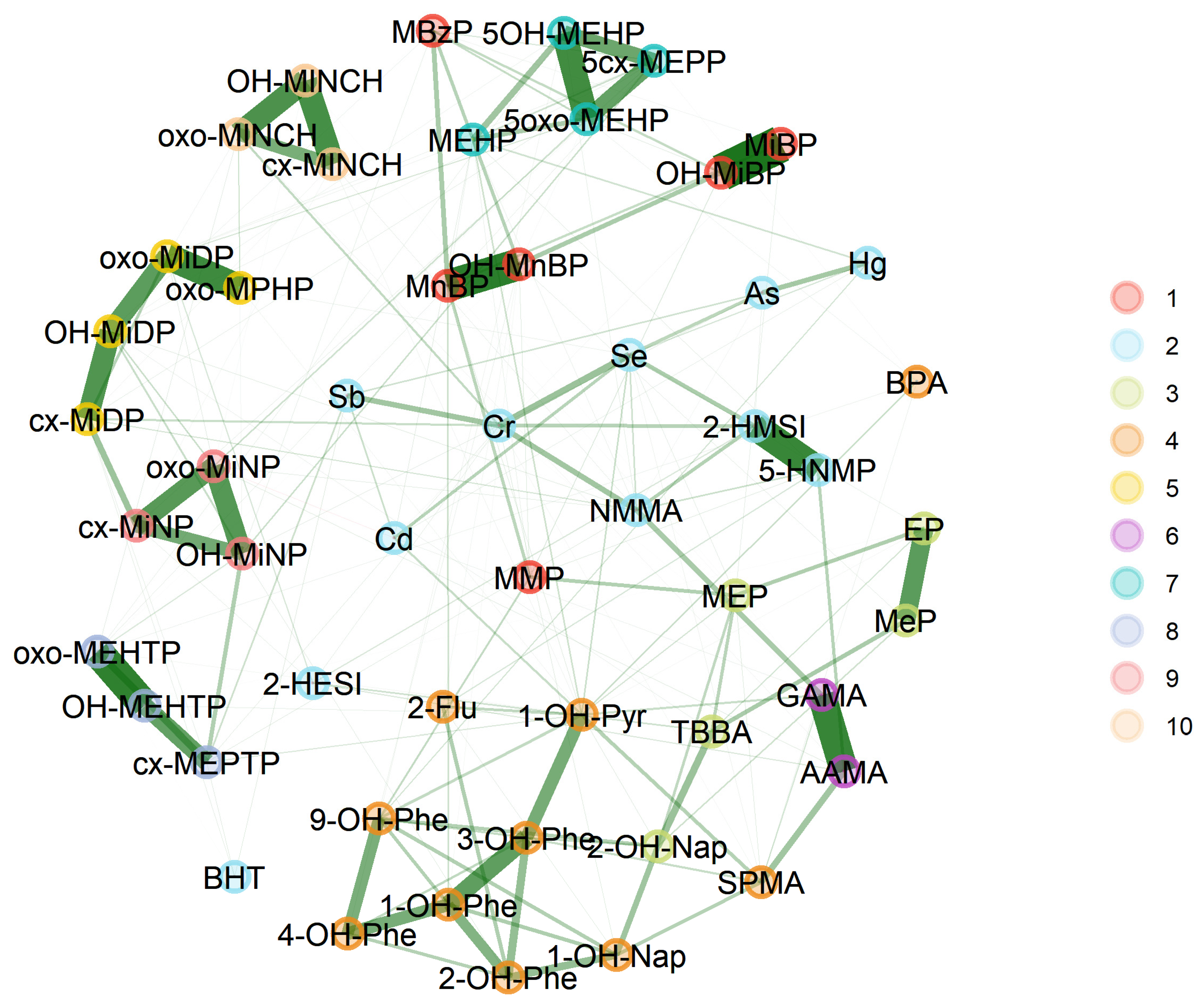
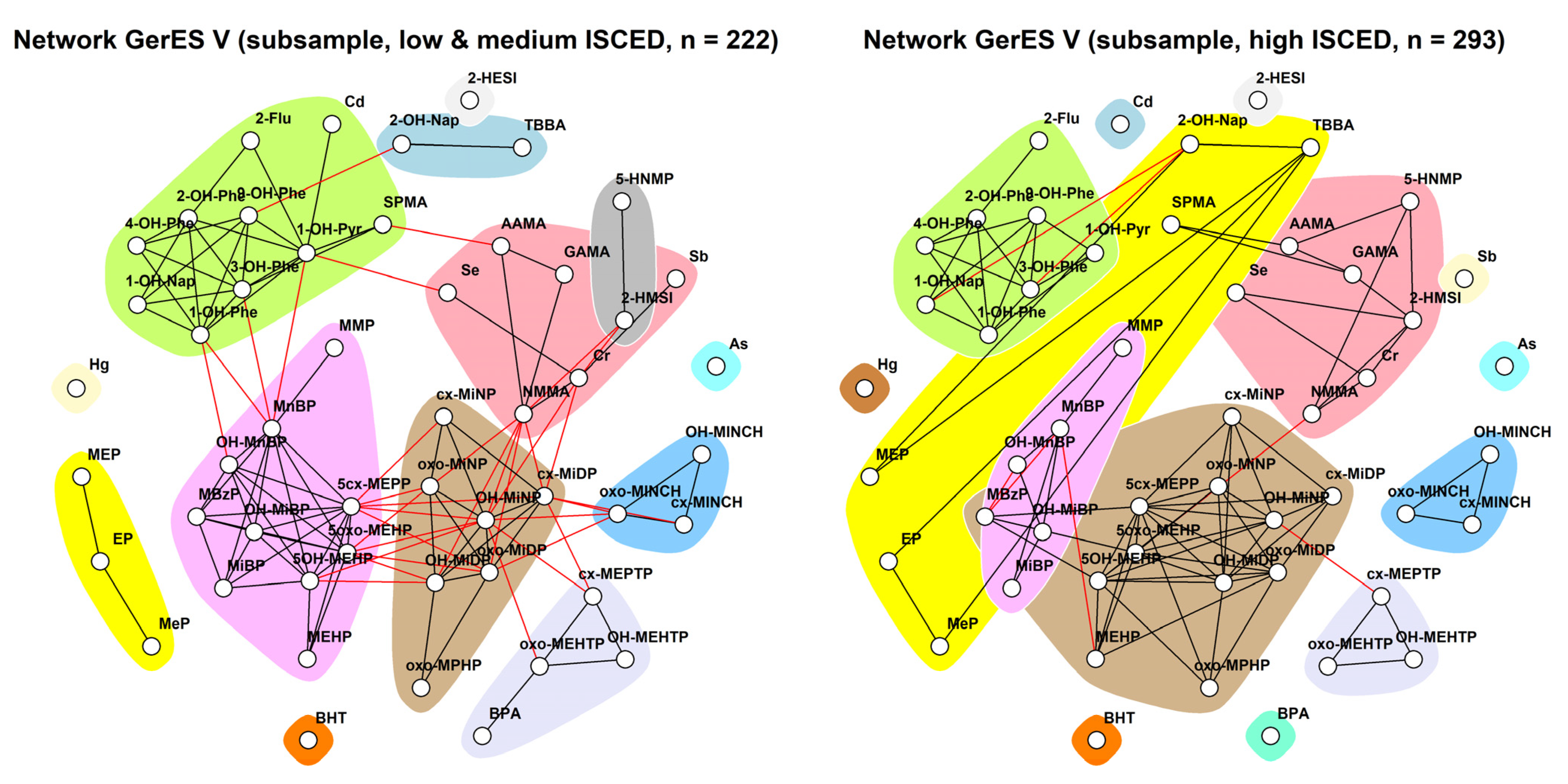
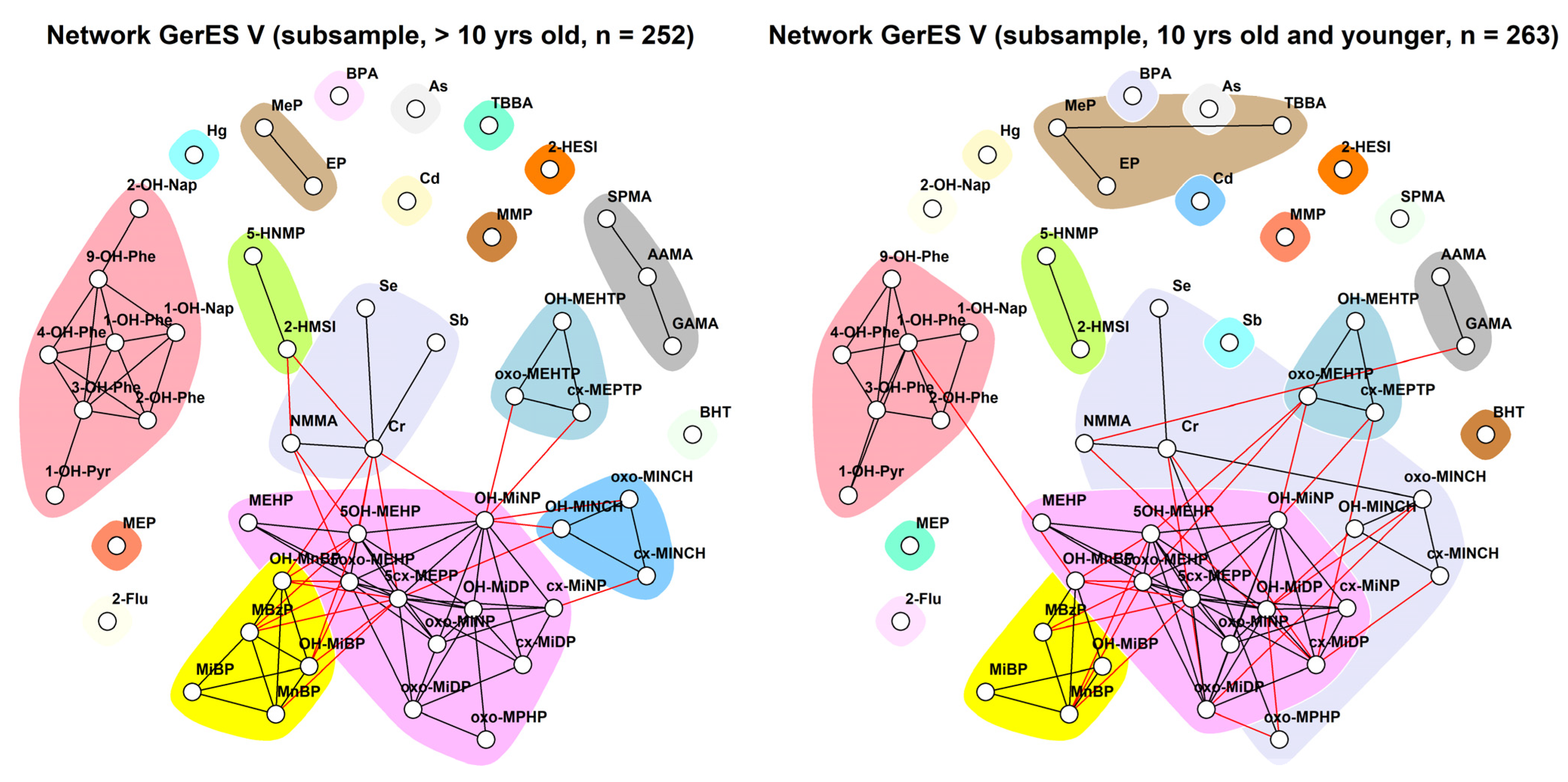
3.2. Network Analysis
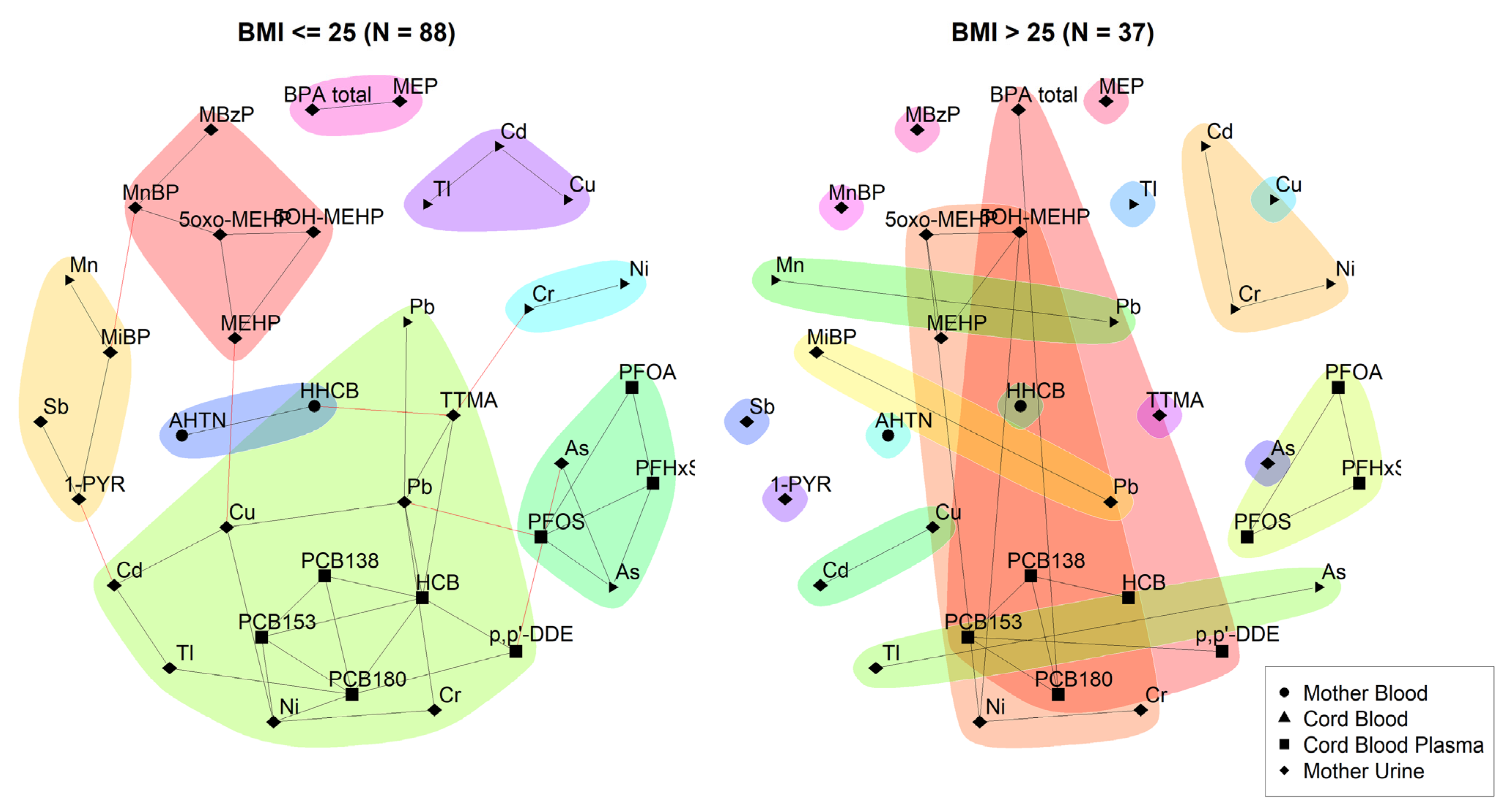
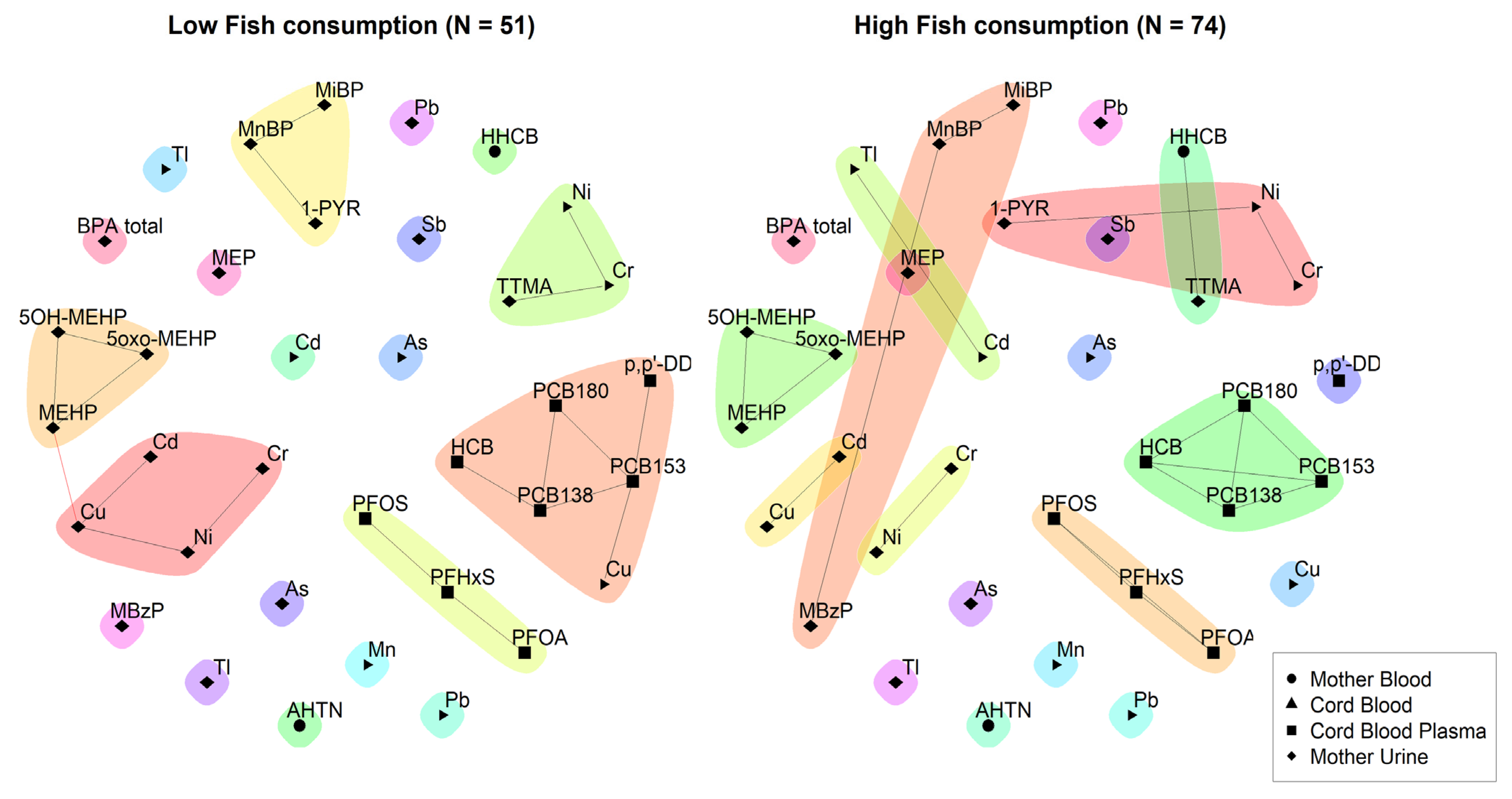
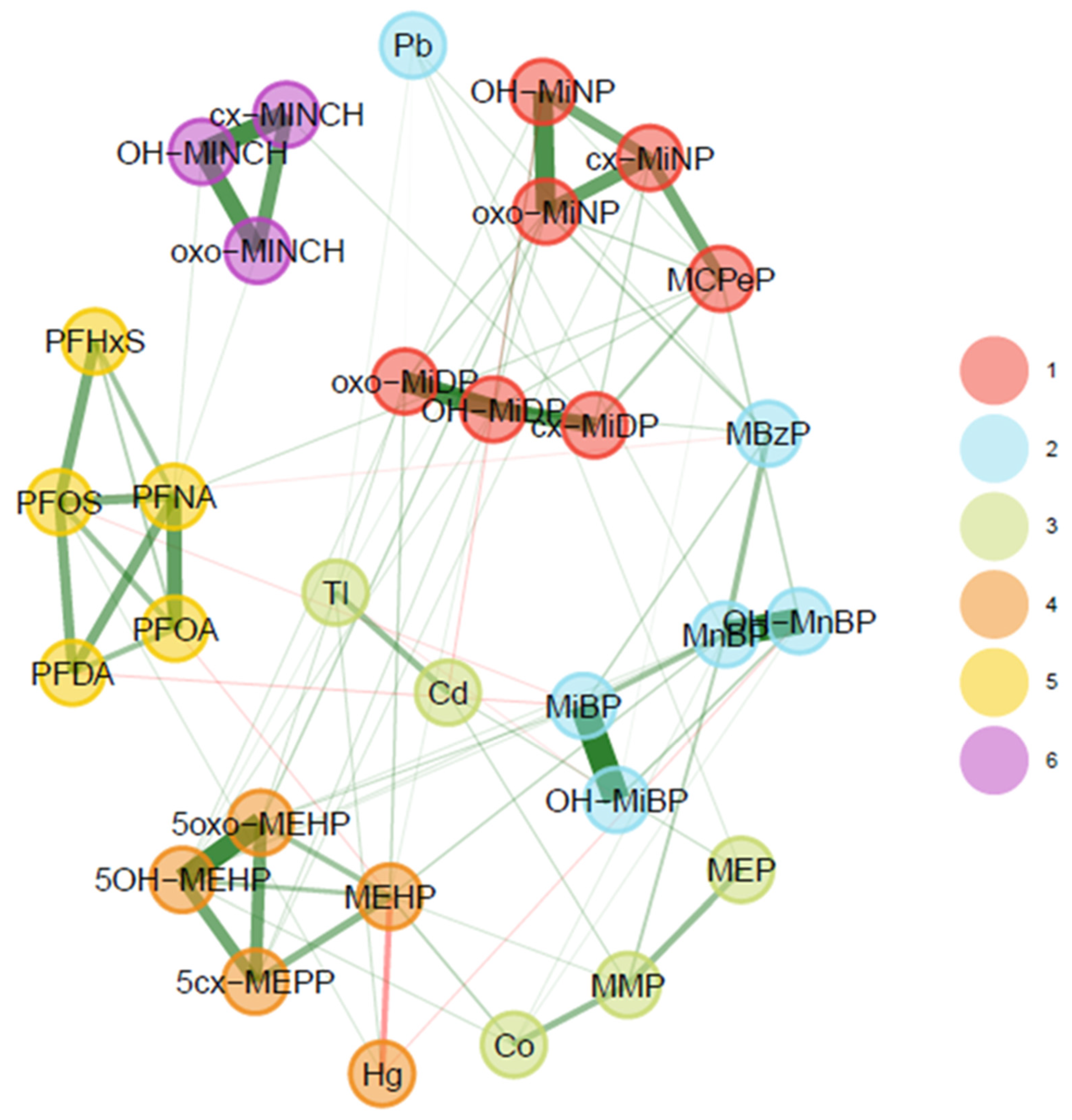
3.2.1. 3xG (Belgium)
3.2.2. CELSPAC—FIREexpo (Czech Republic)
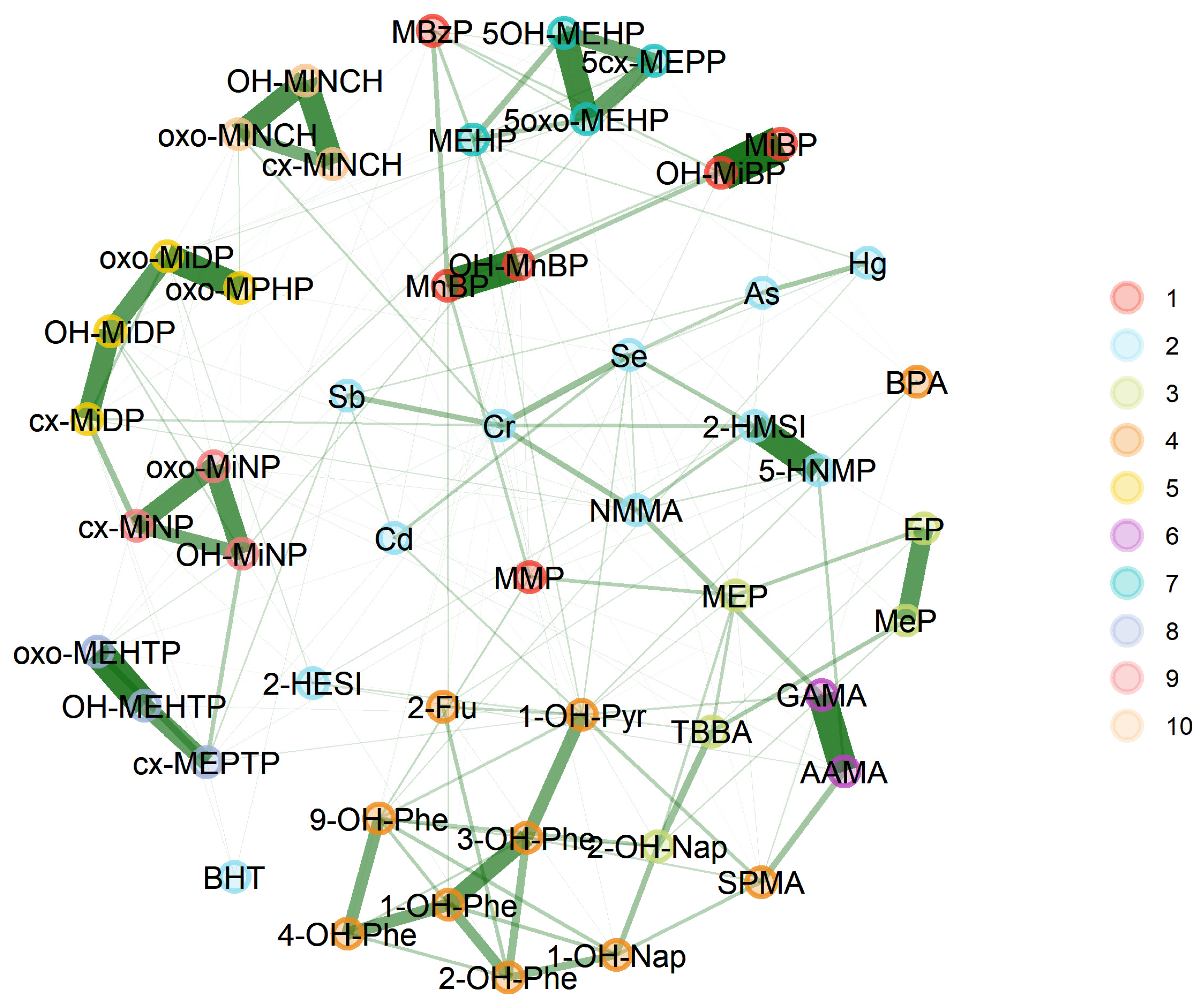
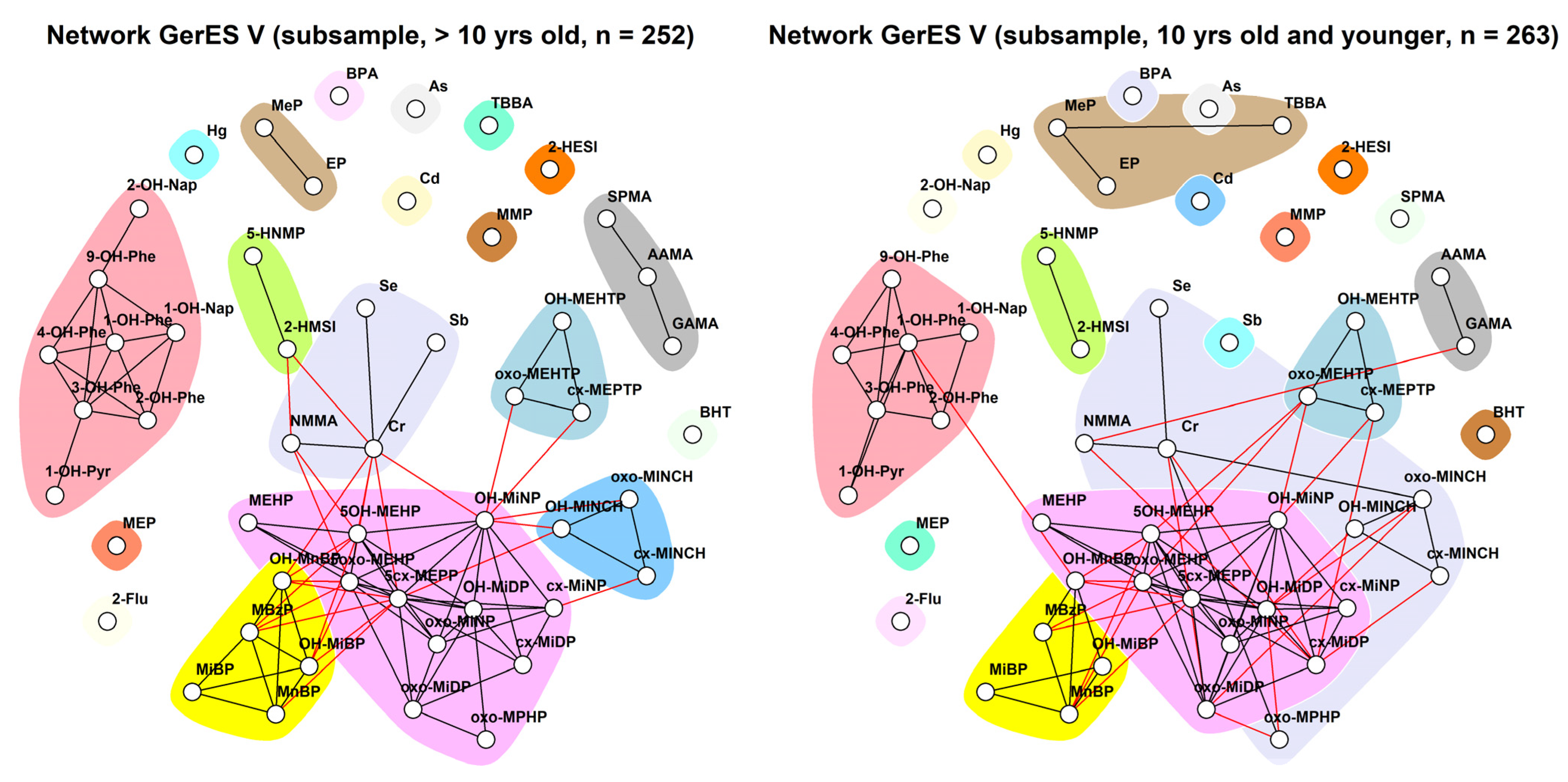
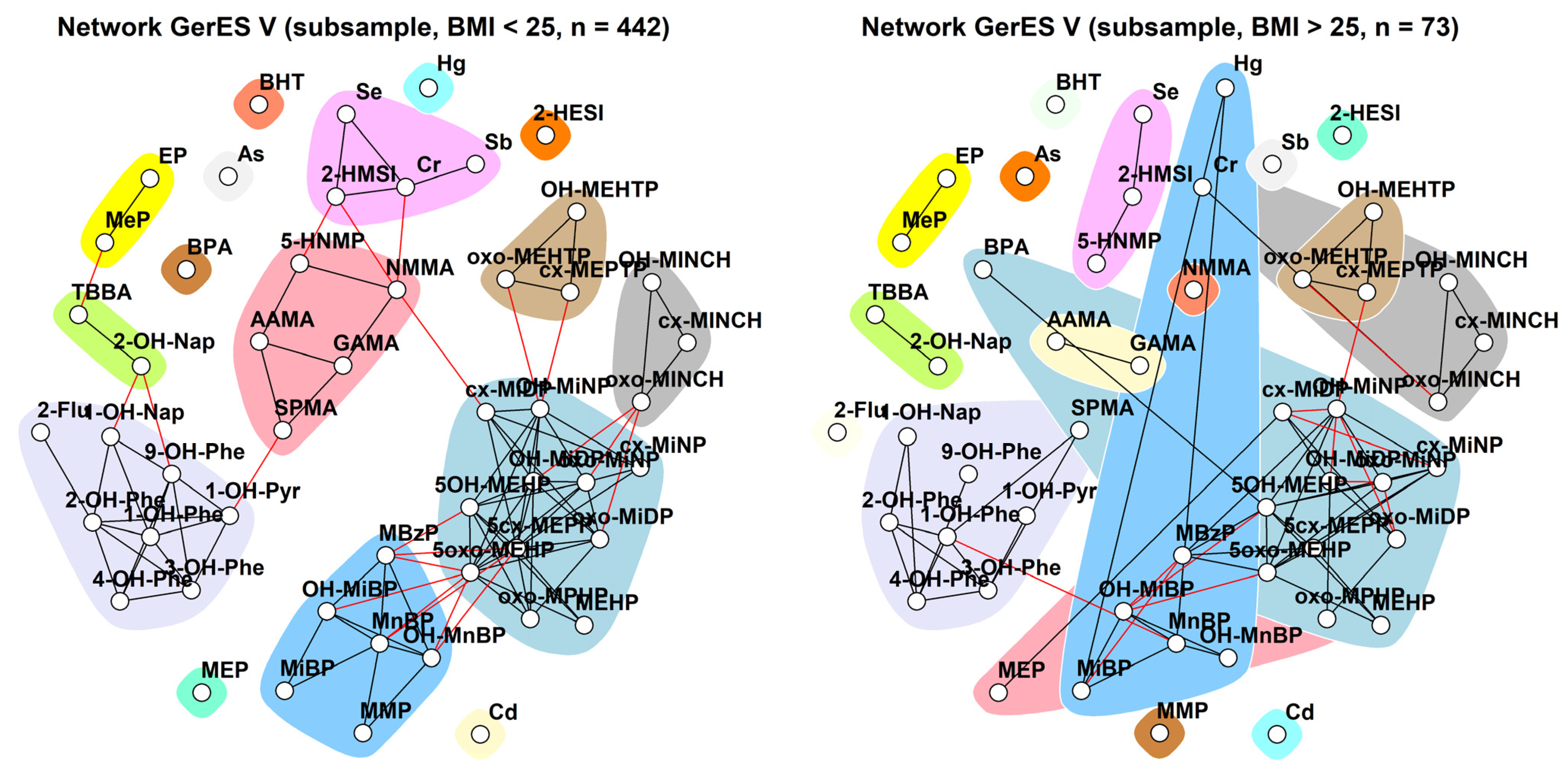
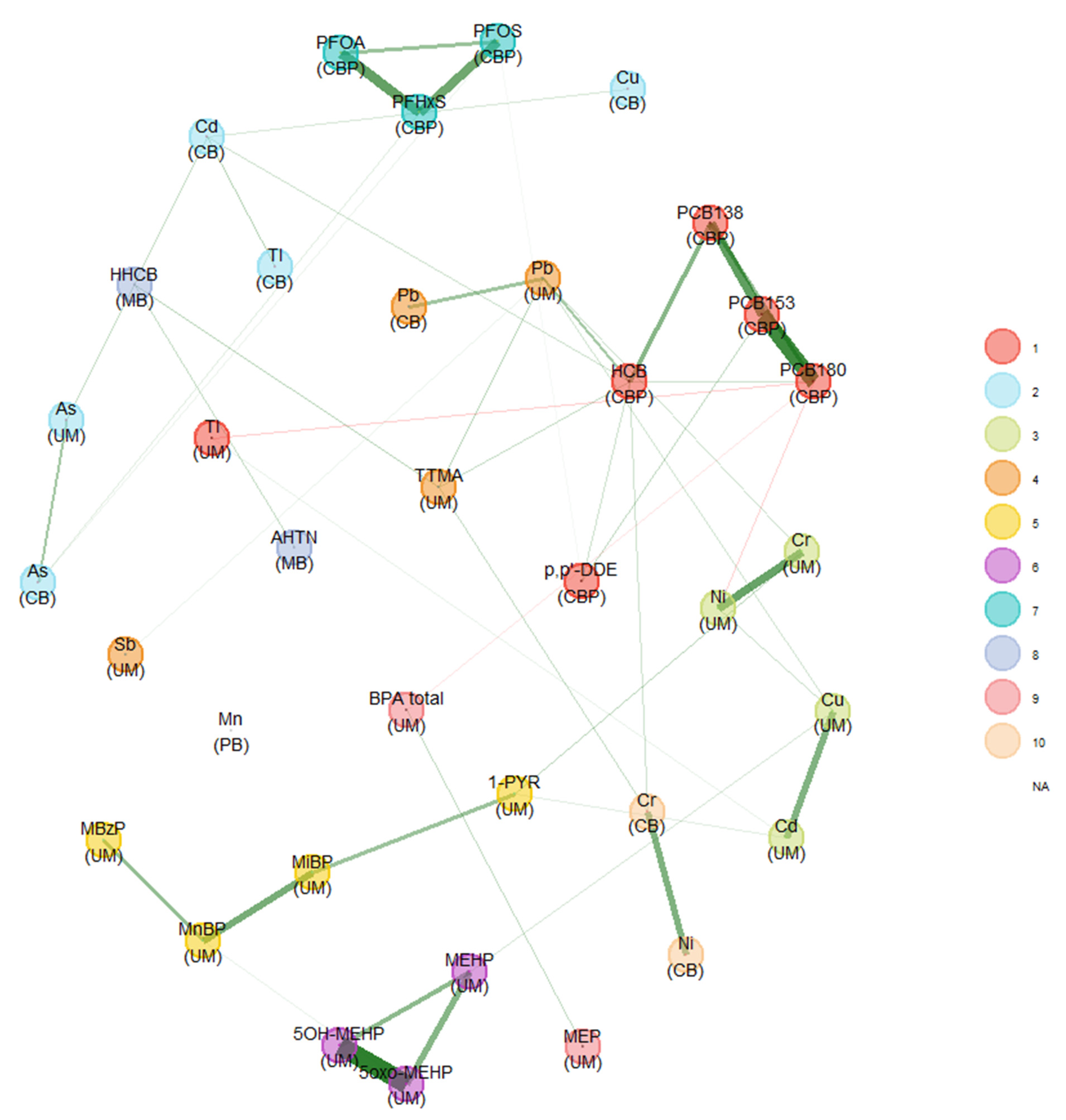
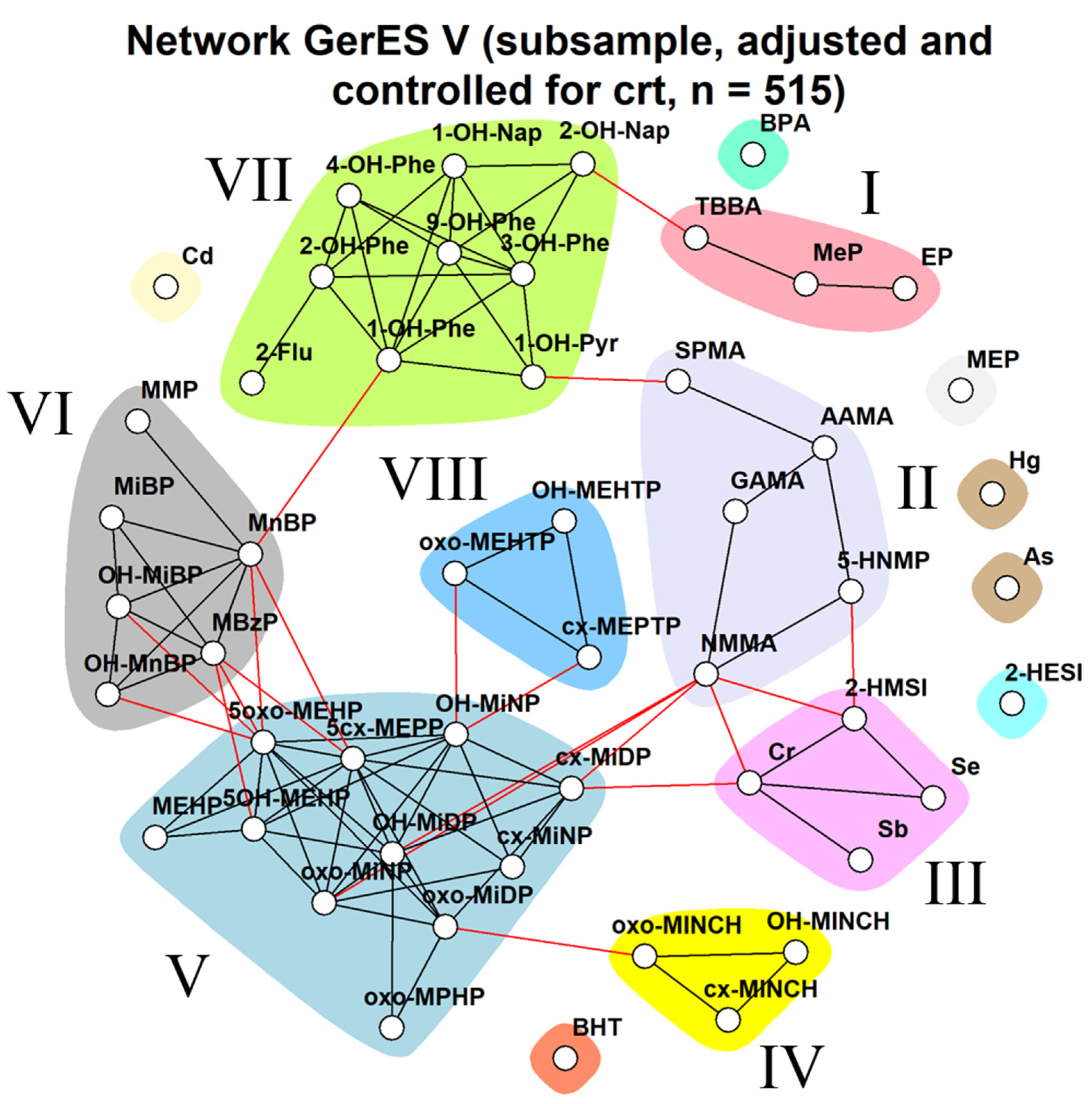
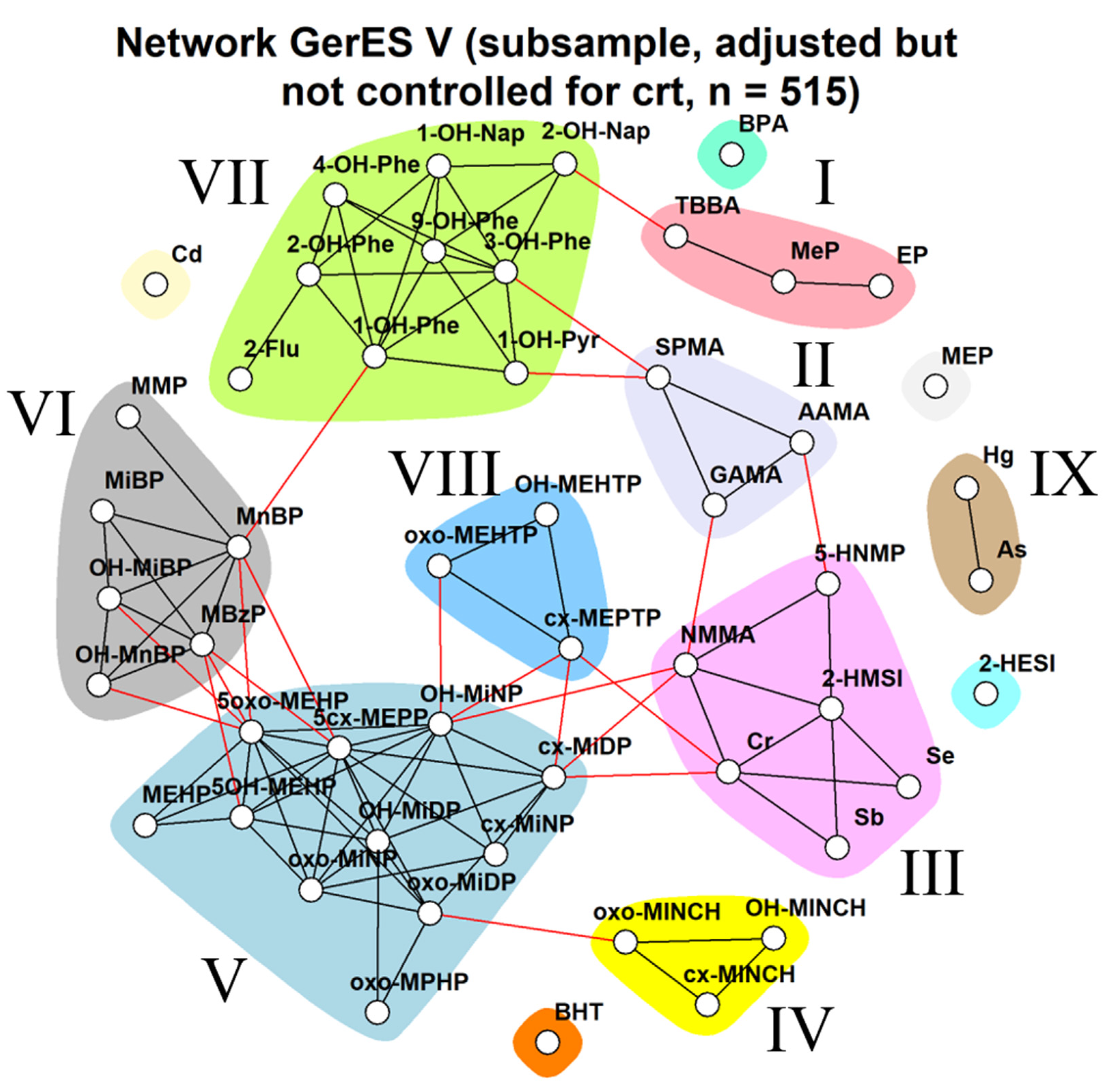
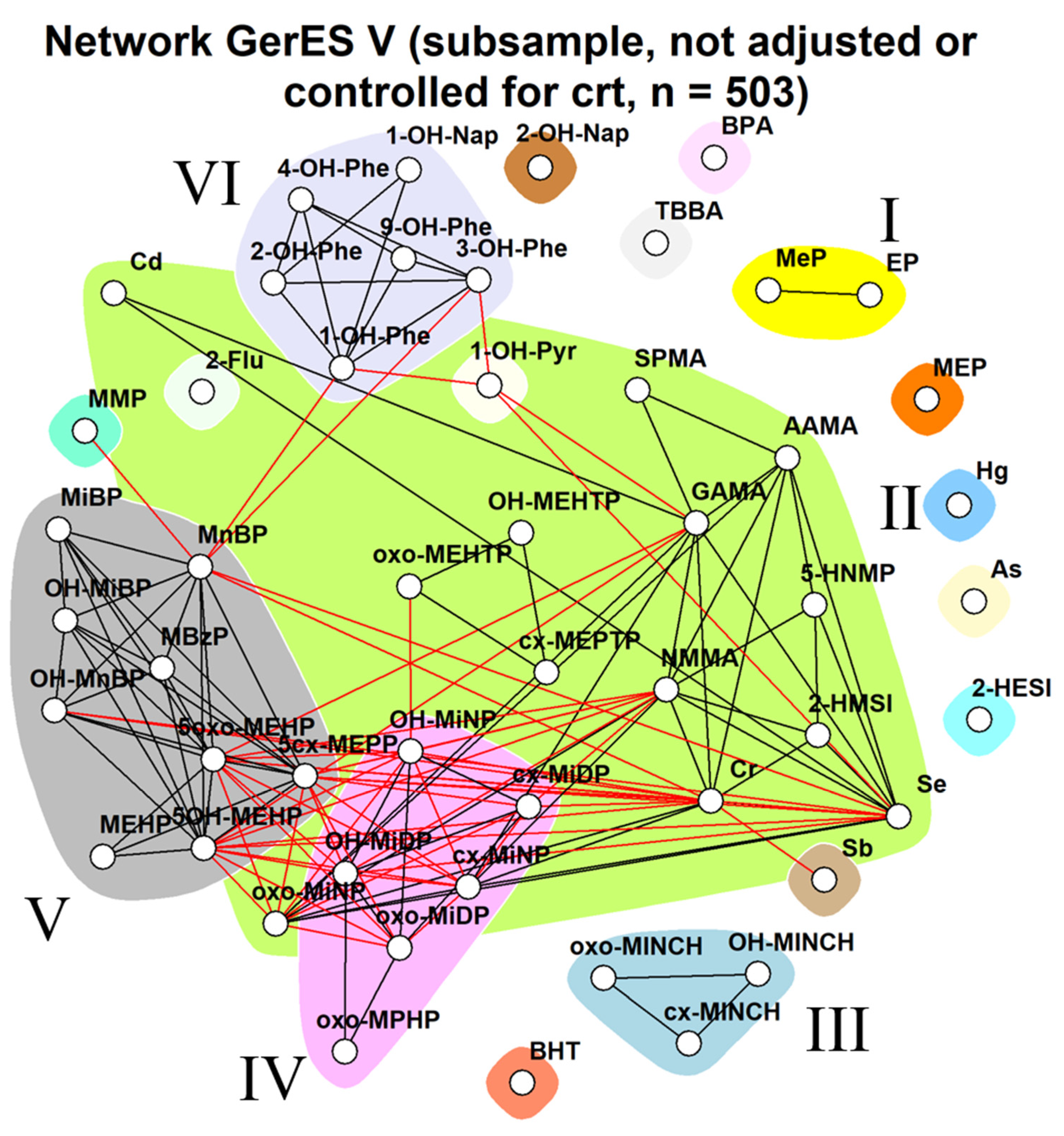
3.2.3. GerES V (Germany)
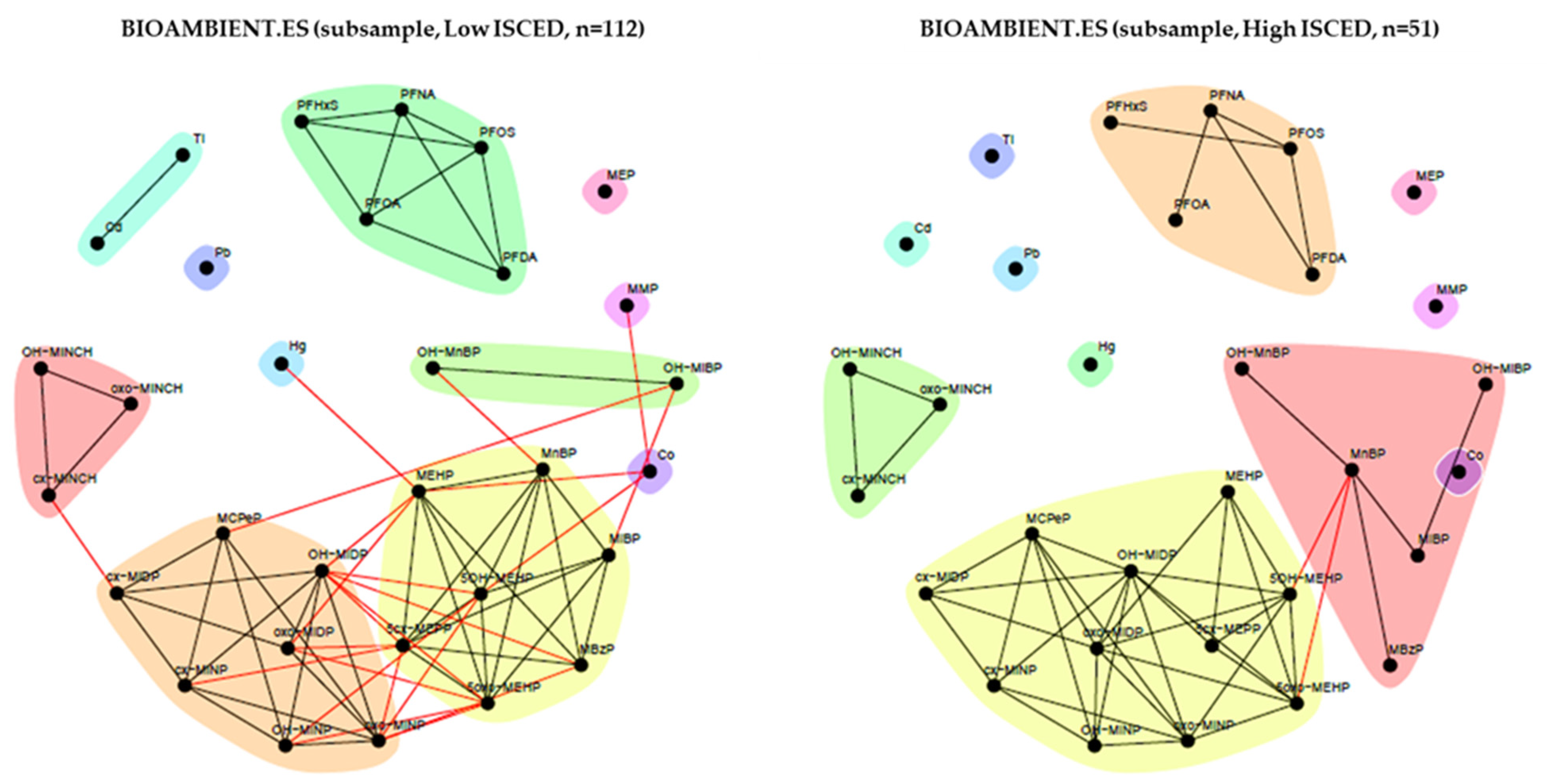
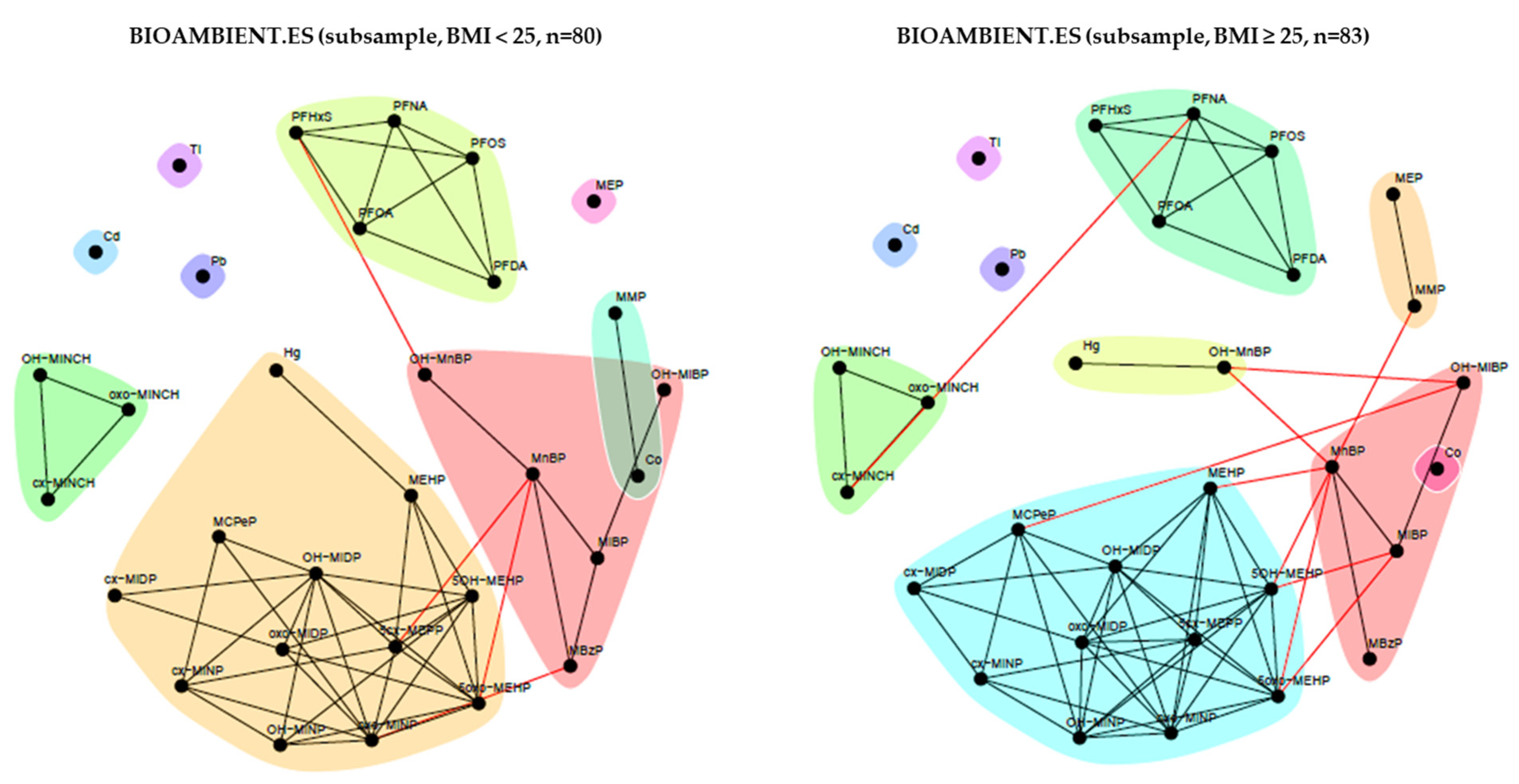
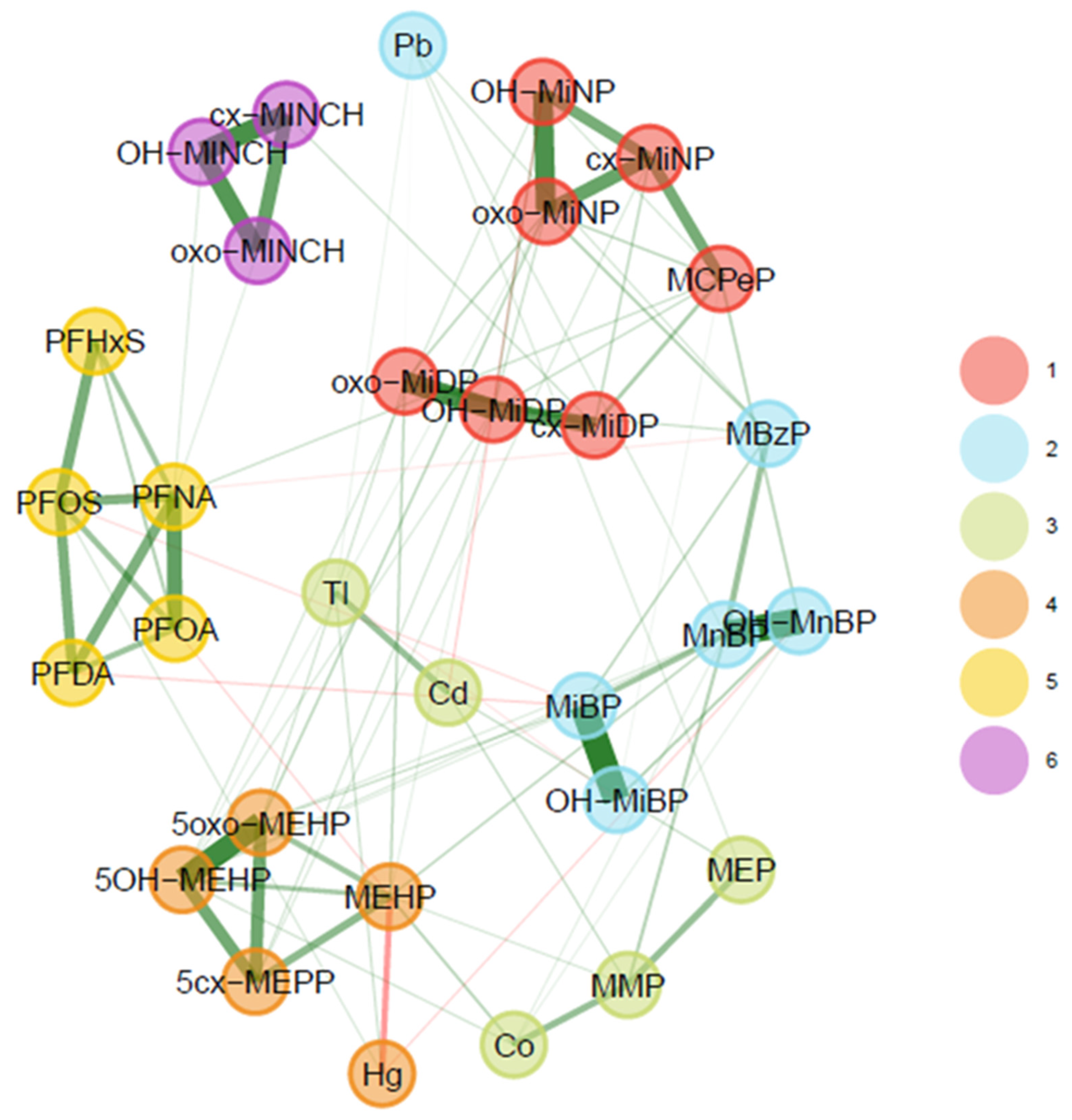
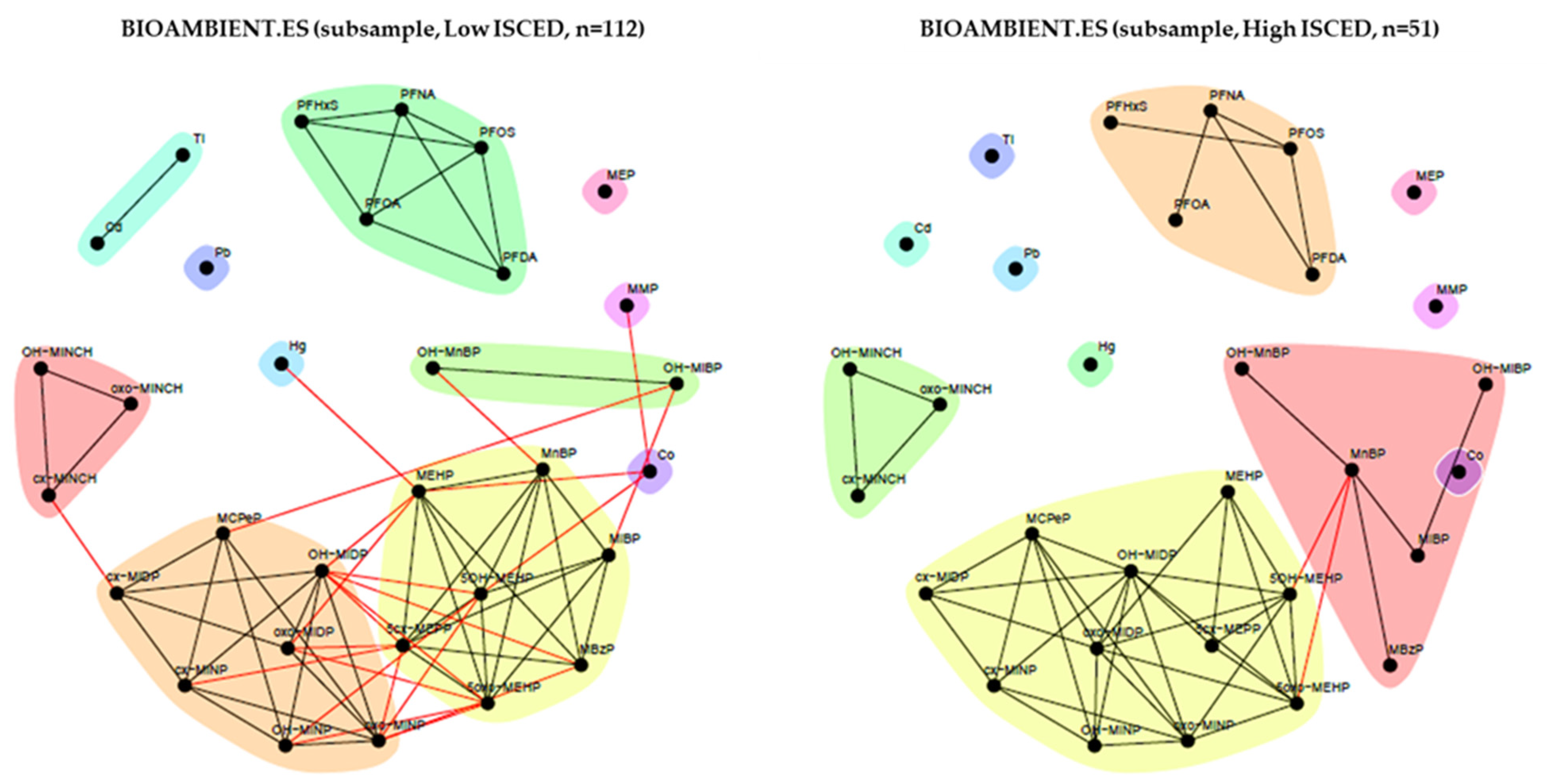
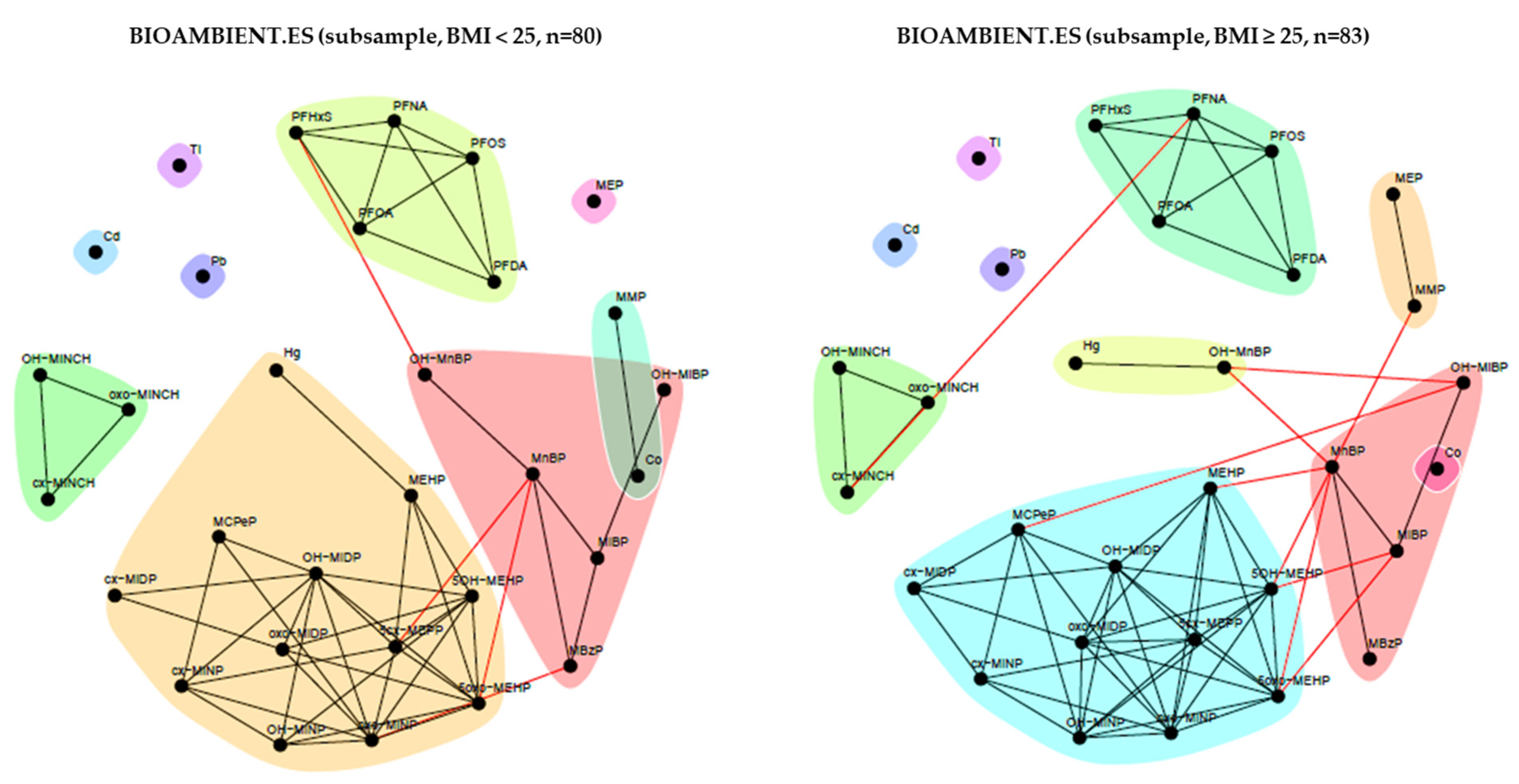
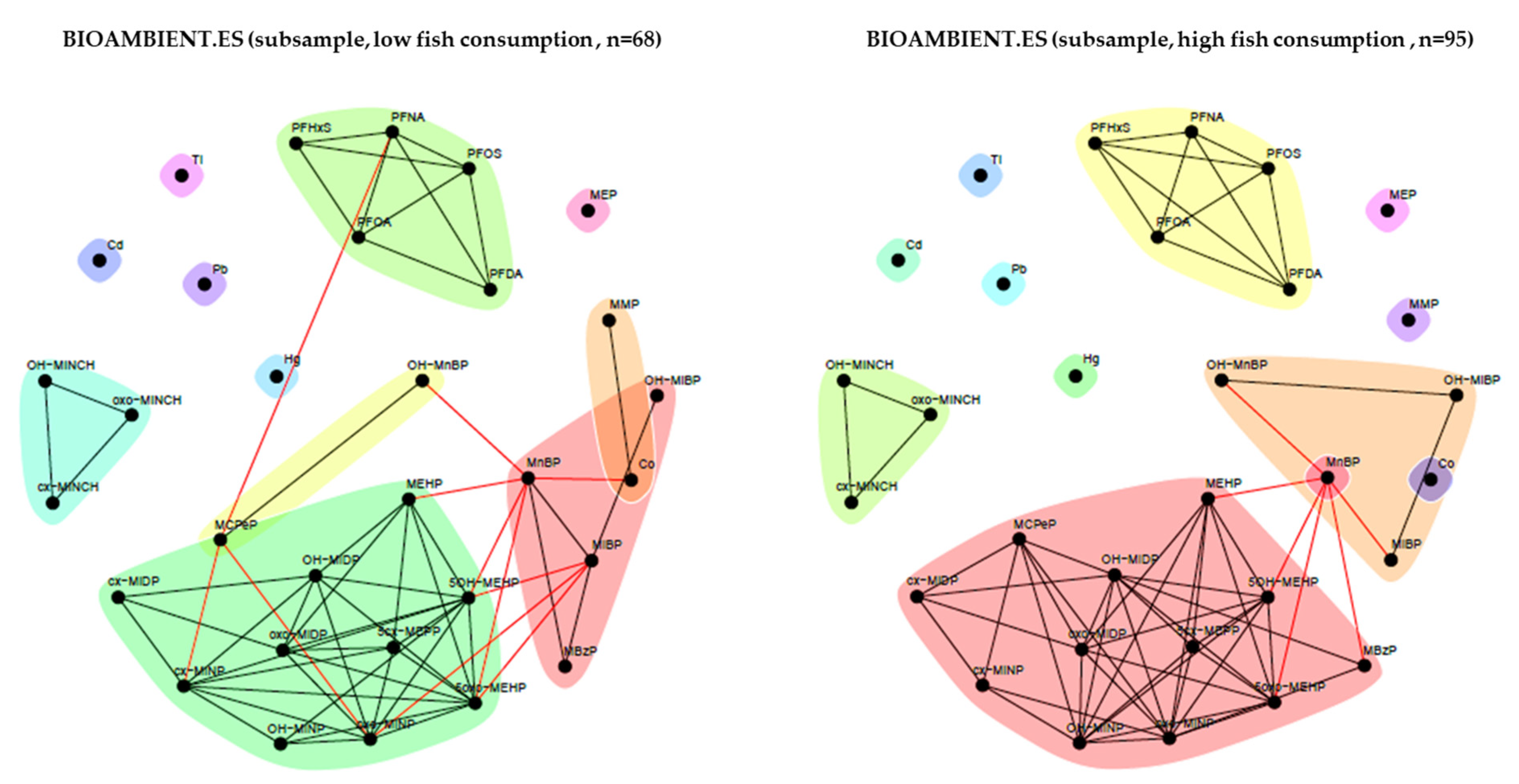
3.2.4. BIOAMBIENT (Spain)
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
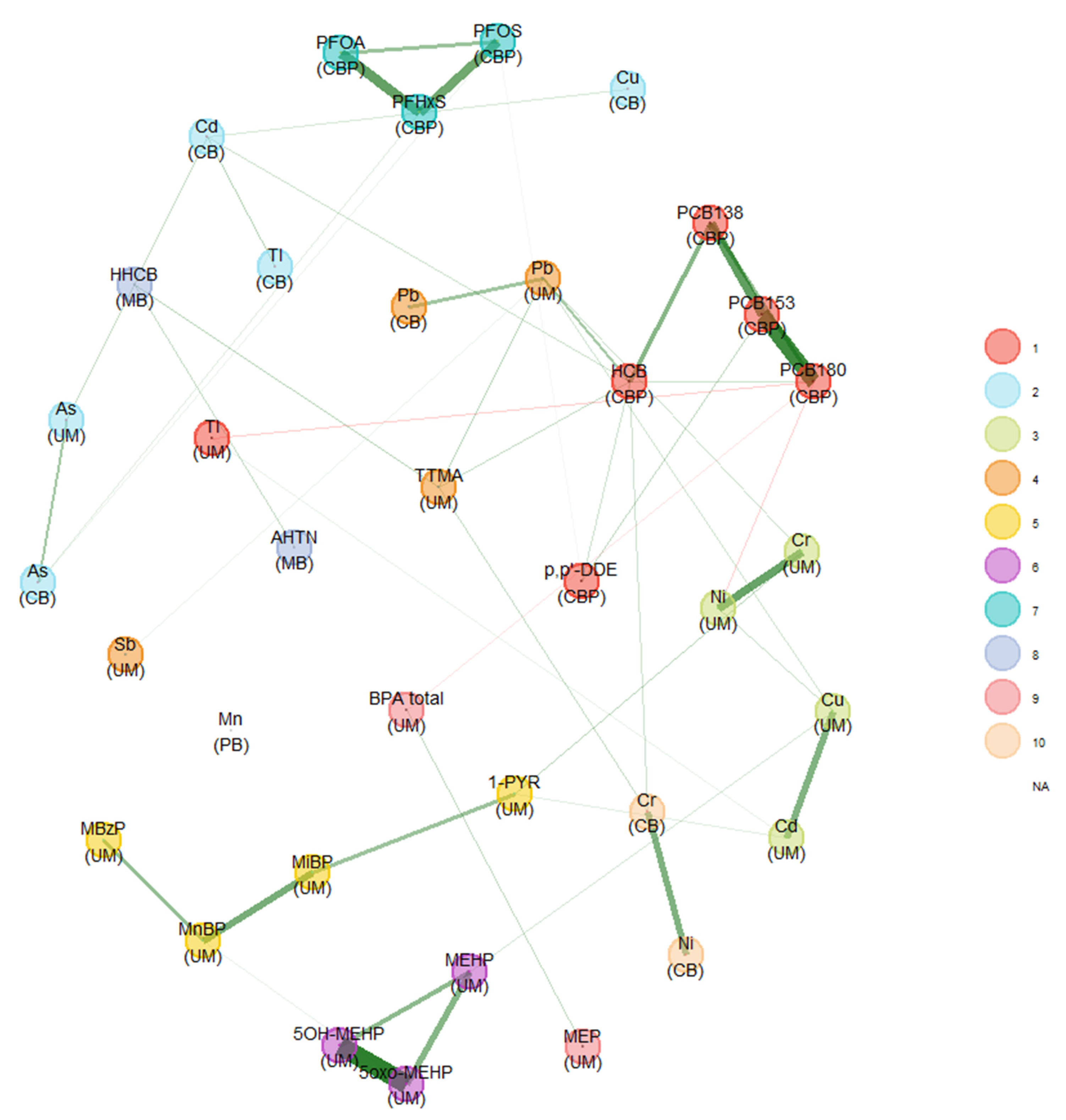
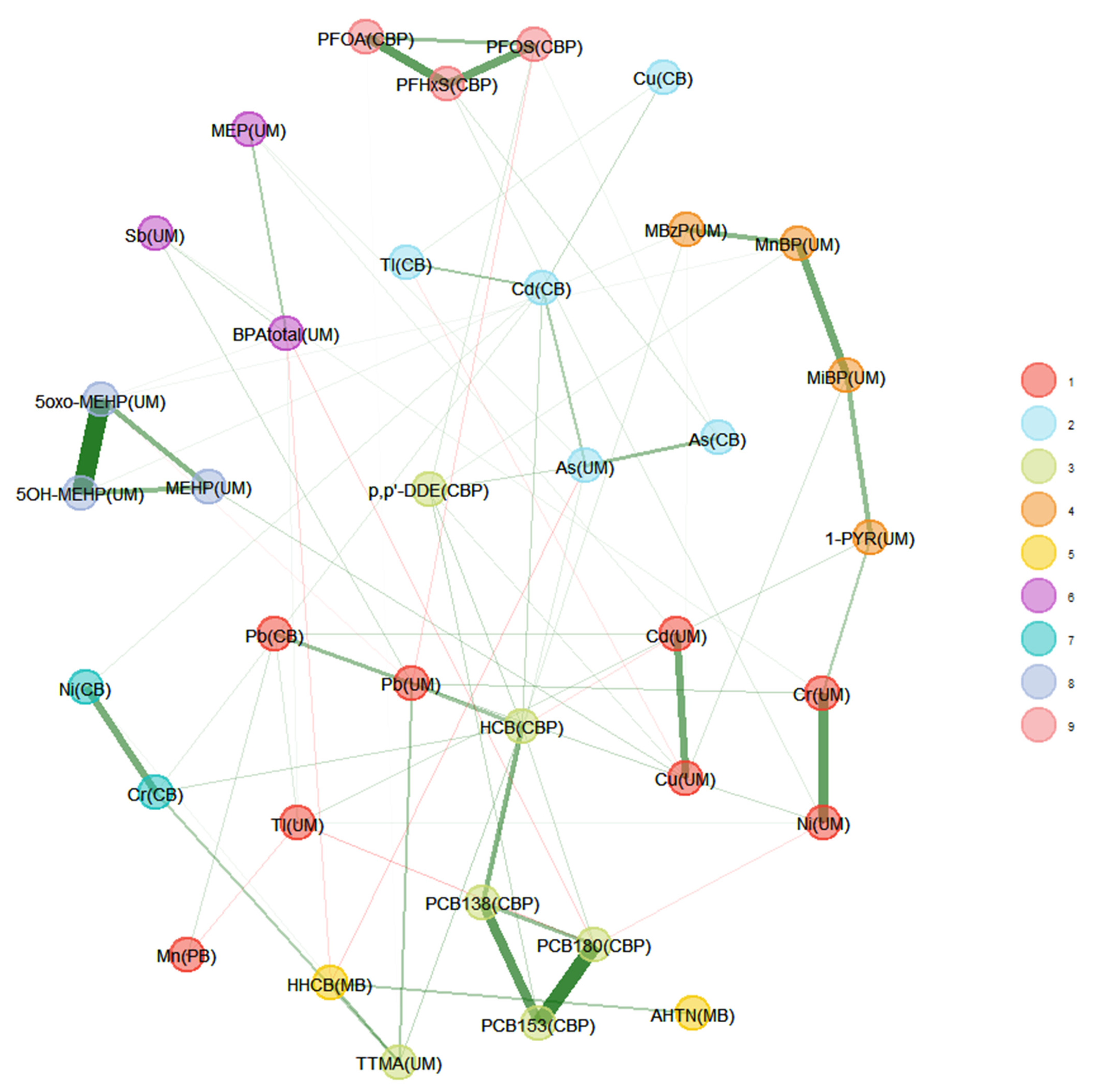
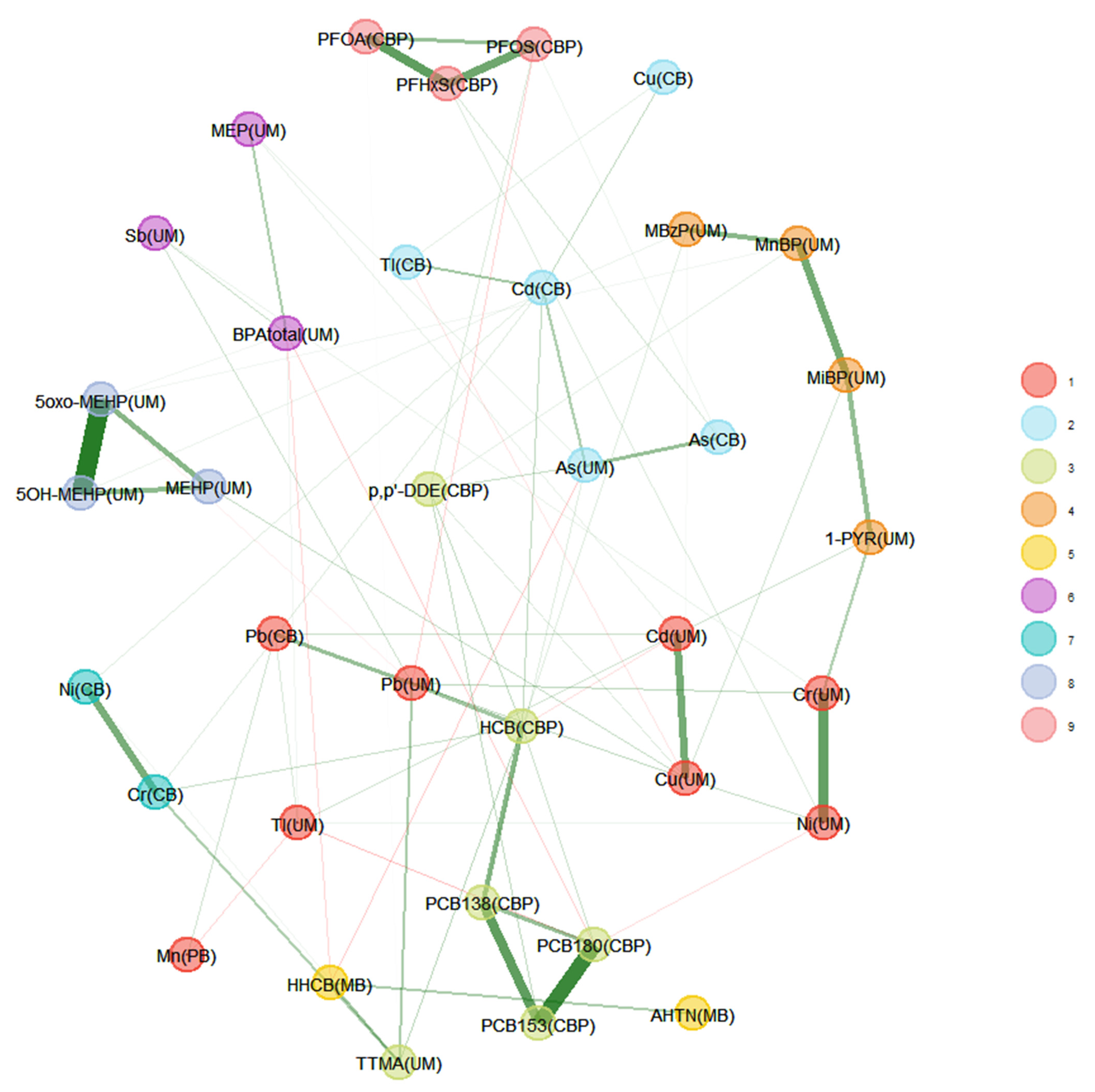
Comparison of the Two Unweighted and Weighted Network Estimation Approaches
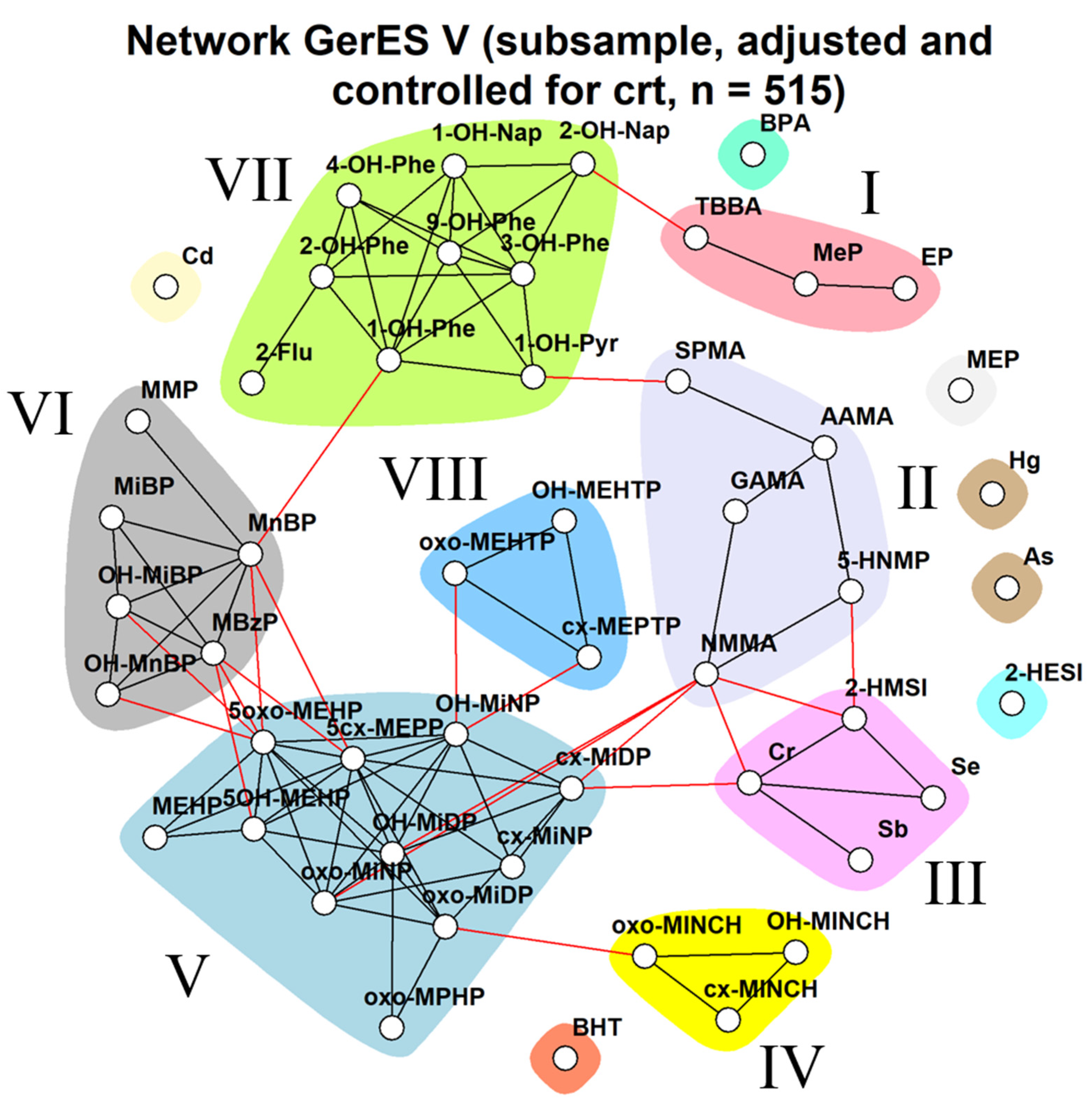
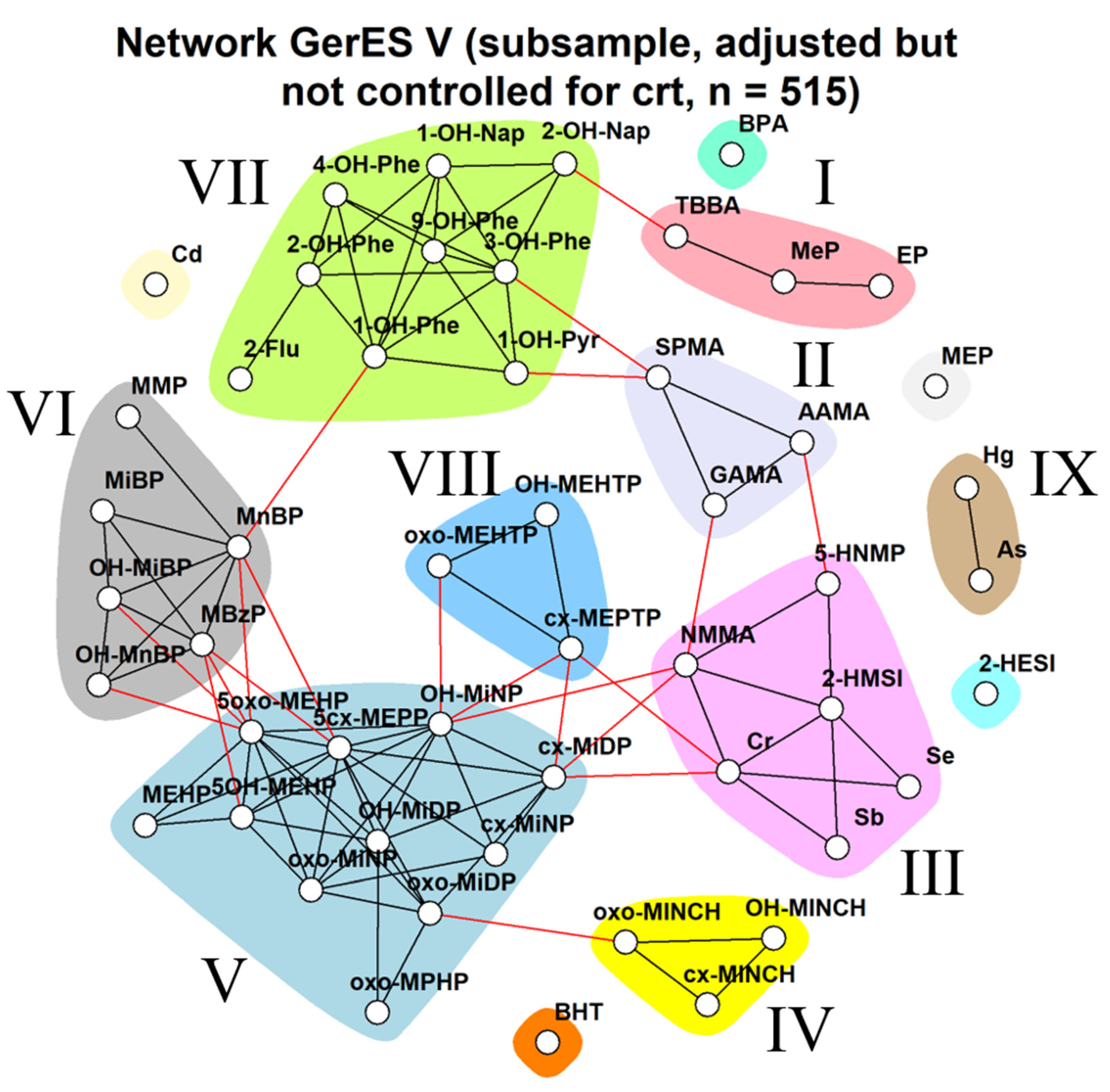
Impact of Different Approaches to Correcting Biomarker Levels against Creatinine Levels
References
- EFSA Scientific Committee; More, S.J.; Bampidis, V.; Benford, D.; Bragard, C.; Hernandez-Jerez, A.; Bennekou, S.H.; Halldorsson, T.I.; Koutsoumanis, K.P.; Lambré, C.; et al. Guidance Document on Scientific criteria for grouping chemicals into assessment groups for human risk assessment of combined exposure to multiple chemicals. EFSA J. 2021, 19, e07033. [Google Scholar] [CrossRef] [PubMed]
- Drakvik, E.; Altenburger, R.; Aoki, Y.; Backhaus, T.; Bahadori, T.; Barouki, R.; Brack, W.; Cronin, M.T.; Demeneix, B.; Bennekou, S.H.; et al. Statement on advancing the assessment of chemical mixtures and their risks for human health and the environment. Environ. Int. 2020, 134, 105267. [Google Scholar] [CrossRef] [PubMed]
- European Commission. Communication from the Commission to the Council: The Combination Effects of Chemicals—Chemical mixtures. 2012, COM(2012) 252 final, 1–10. Available online: https://eur-lex.europa.eu/LexUriServ/LexUriServ.do?uri=COM:2012:0252:FIN:EN:PDF (accessed on 27 January 2023).
- Kienzler, A.; Bopp, S.K.; van der Linden, S.; Berggren, E.; Worth, A. Regulatory assessment of chemical mixtures: Requirements, current approaches and future perspectives. Regul. Toxicol. Pharmacol. 2016, 80, 321–334. [Google Scholar] [CrossRef] [PubMed]
- Rotter, S.; Beronius, A.; Boobis, A.R.; Hanberg, A.; Van Klaveren, J.; Luijten, M.; Machera, K.; Nikolopoulou, D.; Van Der Voet, H.; Zilliacus, J.; et al. Overview on legislation and scientific approaches for risk assessment of combined exposure to multiple chemicals: The potential EuroMix contribution. Crit. Rev. Toxicol. 2018, 48, 796–814. [Google Scholar] [CrossRef] [PubMed]
- Agier, L.; Portengen, L.; Chadeau-Hyam, M.; Basagaña, X.; Giorgis-Allemand, L.; Siroux, V.; Robinson, O.; Vlaanderen, J.; González, J.R.; Nieuwenhuijsen, M.J.; et al. A Systematic Comparison of Linear Regression–Based Statistical Methods to Assess Exposome-Health Associations. Environ. Health Perspect. 2016, 124, 1848–1856. [Google Scholar] [CrossRef]
- Barrera-Gómez, J.; Agier, L.; Portengen, L.; Chadeau-Hyam, M.; Giorgis-Allemand, L.; Siroux, V.; Robinson, O.; Vlaanderen, J.; González, J.R.; Nieuwenhuijsen, M.; et al. A systematic comparison of statistical methods to detect interactions in exposome-health associations. Environ. Health 2017, 16, 74. [Google Scholar] [CrossRef]
- Ottenbros, I.; Govarts, E.; Lebret, E.; Vermeulen, R.; Schoeters, G.; Vlaanderen, J. Network Analysis to Identify Communities Among Multiple Exposure Biomarkers Measured at Birth in Three Flemish General Population Samples. Front. Public Health 2021, 9, 590038. [Google Scholar] [CrossRef]
- Lubin, J.H.; Colt, J.S.; Camann, D.; Davis, S.; Cerhan, J.; Severson, R.K.; Bernstein, L.; Hartge, P. Epidemiologic Evaluation of Measurement Data in the Presence of Detection Limits. Environ. Health Perspect. 2004, 112, 1691–1696. [Google Scholar] [CrossRef] [PubMed]
- van Buuren, S.; Groothuis-Oudshoorn, K. mice: Multivariate Imputation by Chained Equations in R. Journal of Statistical Software 2011, 45, 1–67. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Core Team: Vienna, Austria, 2022; Available online: https://www.R-project.org/ (accessed on 27 January 2023).
- Govarts, E.; Portengen, L.; Lambrechts, N.; Bruckers, L.; Hond, E.D.; Covaci, A.; Nelen, V.; Nawrot, T.S.; Loots, I.; Sioen, I.; et al. Early-life exposure to multiple persistent organic pollutants and metals and birth weight: Pooled analysis in four Flemish birth cohorts. Environ. Int. 2020, 145, 106149. [Google Scholar] [CrossRef] [PubMed]
- Řiháčková, K.; Pindur, A.; Komprdová, K.; Pálešová, N.; Kohoutek, J.; Šenk, P.; Navrátilová, J.; Andrýsková, L.; Šebejová, L.; Hůlek, R.; et al. The exposure of Czech firefighters to perfluoroalkyl substances and polycyclic aromatic hydrocarbons: CELSPAC—FIREexpo case-control human biomonitoring study. Under Review.
- Mauz, E.; Gößwald, A.; Kamtsiuris, P.; Hoffmann, R.; Lange, M.; von Schenck, U.; Allen, J.; Butschalowsky, H.; Frank, L.; Hölling, H.; et al. New data for action. Data collection for KiGGS Wave 2 has been completed. J. Health Monit. 2017, 2. [Google Scholar] [CrossRef]
- Schulz, C.; Kolossa-Gehring, M.; Gies, A. German Environmental Survey for Children and Adolescents 2014-2017 (GerES V)—the environmental module of KiGGS Wave 2. J. Health Monit. 2017, 2. [Google Scholar] [CrossRef]
- Murawski, A.; Roth, A.; Schwedler, G.; Schmied-Tobies, M.I.; Rucic, E.; Pluym, N.; Scherer, M.; Scherer, G.; Conrad, A.; Kolossa-Gehring, M. Polycyclic aromatic hydrocarbons (PAH) in urine of children and adolescents in Germany—human biomonitoring results of the German Environmental Survey 2014–2017 (GerES V). Int. J. Hyg. Environ. Health 2020, 226, 113491. [Google Scholar] [CrossRef]
- Hoffmann, R.; Lange, M.; Butschalowsky, H.; Houben, R.; Schmich, P.; Allen, J.; Kuhnert, R.; Schaffrath Rosario, A.; Gößwald, A. KiGGS Wave 2 cross-sectional study—participant acquisition, response rates and representativeness. J. Health Monit. 2018, 3, 78–91. [Google Scholar] [CrossRef] [PubMed]
- Pérez-Gómez, B.; Bioambient.Es, O.B.O.; Pastor-Barriuso, R.; Cervantes-Amat, M.; Esteban, M.; Ruiz-Moraga, M.; Aragonés, N.; Pollán, M.; Navarro, C.; Calvo, E.; et al. BIOAMBIENT.ES study protocol: Rationale and design of a cross-sectional human biomonitoring survey in Spain. Environ. Sci. Pollut. Res. 2013, 20, 1193–1202. [Google Scholar] [CrossRef] [PubMed]
- Csárdi, G.; Nepusz, T. The igraph software package for complex network research. InterJ. Complex Syst. 2006, 1695, 1–9. [Google Scholar]
- Zhao, T.; Liu, H.; Roeder, K.; Lafferty, J.; Wasserman, L. The huge Package for High-dimensional Undirected Graph Estimation in R. J. Mach. Learn. Res. 2012, 13, 1059–1062. [Google Scholar]
- Golino, H.; Christensen, A.P. EGAnet: Exploratory Graph Analysis – A Framework for Estimating the Number of Dimensions in Multivariate Data Using Network Psychometrics, R Package Version 1.1.1. 2022. Available online: https://cran.r-project.org/web/packages/EGAnet/EGAnet.pdf (accessed on 27 January 2023).
- Christensen, A.P.; Golino, H. Estimating the Stability of Psychological Dimensions via Bootstrap Exploratory Graph Analysis: A Monte Carlo Simulation and Tutorial. Psych 2021, 3, 479–500. [Google Scholar] [CrossRef]
- Golino, H.; Moulder, R.; Shi, D.; Christensen, A.P.; Garrido, L.E.; Nieto, M.D.; Nesselroade, J.; Sadana, R.; Thiyagarajan, J.A.; Boker, S.M. Entropy Fit Indices: New Fit Measures for Assessing the Structure and Dimensionality of Multiple Latent Variables. Multivar. Behav. Res. 2020, 56, 874–902. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. Sparse inverse covariance estimation with the graphical lasso. Biostatistics 2007, 9, 432–441. [Google Scholar] [CrossRef]
- Liu, H.; Roeder, K.; Wasserman, L. Stability Approach to Regularization Selection (StARS) for High Dimensional Graphical Models. Adv. Neural Inf. Process. Syst. 2010, 24, 1432–1440. [Google Scholar] [PubMed]
- Orman, G.K.; Labatut, V. A Comparison of Community Detection Algorithms on Artificial Networks; Springer: Berlin/Heidelberg, Germany, 2009; pp. 242–256. [Google Scholar]
- Pons, P.; Latapy, M. Computing Communities in Large Networks Using Random Walks. In International Symposium on Computer and Information Sciences; Springer: Heidelberg, Germany, 2005; pp. 284–293. [Google Scholar]
- Rísová, V. The pathway of lead through the mother’s body to the child. Interdiscip. Toxicol. 2019, 12, 1–6. [Google Scholar] [CrossRef]
- Vahter, M. Health Effects of Early Life Exposure to Arsenic. Basic Clin. Pharmacol. Toxicol. 2008, 102, 204–211. [Google Scholar] [CrossRef] [PubMed]
- Benjamin, S.; Masai, E.; Kamimura, N.; Takahashi, K.; Anderson, R.C.; Faisal, P.A. Phthalates impact human health: Epidemiological evidences and plausible mechanism of action. J. Hazard. Mater. 2017, 340, 360–383. [Google Scholar] [CrossRef]
- Schettler, T. Human exposure to phthalates via consumer products. Int. J. Androl. 2006, 29, 134–139. [Google Scholar] [CrossRef] [PubMed]
- Fisher, M.; Arbuckle, T.E.; MacPherson, S.; Braun, J.M.; Feeley, M.; Gaudreau, E. Phthalate and BPA Exposure in Women and Newborns through Personal Care Product Use and Food Packaging. Environ. Sci. Technol. 2019, 53, 10813–10826. [Google Scholar] [CrossRef] [PubMed]
- Andra, S.S.; Makris, K.C. Incorporating potable water sources and use habits into surveys that improve surrogate exposure estimates for water contaminants: The case of bisphenol A. J. Water Health 2013, 12, 81–93. [Google Scholar] [CrossRef]
- Llop, S.; Ballester, F.; Estarlich, M.; Ibarluzea, J.; Manrique, A.; Rebagliato, M.; Esplugues, A.; Iniguez, C. Urinary 1-hydroxypyrene, air pollution exposure and associated life style factors in pregnant women. Sci. Total. Environ. 2008, 407, 97–104. [Google Scholar] [CrossRef]
- Horvath, S. Weighted Network Analysis: Applications in Genomics and Systems Biology; Springer New York: New York, NY, USA, 2011; p. 421. [Google Scholar]
- Bodinier, B.; Filippi, S.; Haugdahl Nost, T.; Chiquet, J.; Chadeau-Hyam, M. Automated calibration for stability selection in penalised regression and graphical models: A multi-OMICs network application exploring the molecular response to tobacco smoking. arXiv 2021. [Google Scholar] [CrossRef]
- European Commission. Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation). 2016. [Google Scholar]
- O’Brien, K.; Upson, K.; Cook, N.R.; Weinberg, C. Environmental Chemicals in Urine and Blood: Improving Methods for Creatinine and Lipid Adjustment. Environ. Health Perspect. 2016, 124, 220–227. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Substance Group | Biomarker | 3XG (Belgium) | CELSPAC—FIREexpo; Controls (Czech Republic) | GerES V (Germany) | BIOAMBIENT.ES (Spain) | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Distribution | % < LOQ | P25 | P50 | P75 | P95 | % < LOQ | P25 | P50 | P75 | P95 | % < LOQ | P25 | P50 | P75 | P95 | % < LOQ | P25 | P50 | P75 | P95 | |
| Elements | Cd | 0% | 0.21 | 0.28 | 0.37 | 0.54 | 26% | < LOQ | 0.06 | 0.09 | 0.15 | 2.5% | 0.12 | 0.2 | 0.38 | 0.72 | |||||
| Cr | 1.6% | 0.26 | 0.49 | 0.82 | 1.76 | 7.8% | 0.26 | 0.34 | 0.49 | 0.77 | |||||||||||
| Hg | 5.1% | 0.04 | 0.06 | 0.1 | 0.26 | 0.68% | 0.56 | 0.99 | 1.58 | 2.75 | |||||||||||
| Sb | 18% | 0.03 | 0.04 | 0.06 | 0.15 | 21% | 0.03 | 0.05 | 0.07 | 0.13 | |||||||||||
| As | 0% | 6.72 | 13.89 | 38.79 | 81.22 | 0% | 4.35 | 6.89 | 14.2 | 55.2 | |||||||||||
| Pb | 0% | 0.64 | 0.84 | 1.14 | 1.7 | 2.6% | 0.43 | 0.7 | 1.04 | 2.36 | |||||||||||
| Tl | 0% | 0.18 | 0.22 | 0.26 | 0.35 | 11.35% | 0.08 | 0.11 | 0.16 | 0.26 | |||||||||||
| Phthalate substitute | OH-DINCH | 0.19% | 0.98 | 2.13 | 4.66 | 14.7 | 4.91% | 0.29 | 0.7 | 6.81 | 19.82 | ||||||||||
| oxo-DINCH | 1.55% | 0.39 | 0.93 | 2.03 | 7.16 | 13.5% | 0.11 | 0.35 | 1.19 | 11.87 | |||||||||||
| cx-MINCH | 0.19% | 0.49 | 1.02 | 2.11 | 7.8 | 3.68% | 0.26 | 0.43 | 1.22 | 8.21 | |||||||||||
| Phthalates | MEHP | 2.4% | 1.75 | 2.53 | 4.33 | 8.42 | 13.0% | 0.71 | 1.22 | 2.04 | 4.19 | 3.68% | 2.47 | 4.09 | 6.63 | 14.9 | |||||
| 5OH-MEHP | 0% | 6.67 | 10.08 | 13.75 | 38.04 | 0% | 5.87 | 8.98 | 13.94 | 28.8 | 0% | 11.54 | 18.44 | 26.26 | 56.6 | ||||||
| 5oxo-MEHP | 0% | 4.39 | 7.18 | 9.69 | 22.98 | 0% | 4.08 | 6.42 | 10.49 | 21.6 | 0.61% | 7.74 | 11.45 | 17.03 | 35.71 | ||||||
| 5cx-MEPP | 0% | 6.1 | 9.92 | 16.9 | 35.8 | 0% | 12.82 | 18.88 | 28.15 | 54.27 | |||||||||||
| MBzP | 0% | 3.79 | 7.1 | 11.97 | 22.59 | 0.39% | 1.45 | 2.38 | 4.75 | 17.5 | 1.23% | 3.16 | 5.09 | 8.98 | 28.53 | ||||||
| MnBP | 0% | 23.36 | 34 | 51.35 | 91.75 | 0% | 12.04 | 18.18 | 28.67 | 54.8 | 0.61% | 9.63 | 14.74 | 22.23 | 41.53 | ||||||
| OH-MnBP | 0.78% | 1.25 | 2.12 | 3.49 | 7.27 | 2.45% | 1.08 | 1.71 | 2.44 | 5.04 | |||||||||||
| MiBP | 0% | 43.16 | 60 | 94.4 | 288.5 | 0% | 13.54 | 21.36 | 33.58 | 87.2 | 0% | 16.33 | 23.71 | 34.19 | 72.73 | ||||||
| OH-MiBP | 0% | 4.7 | 7.52 | 12.17 | 30.2 | 0% | 6.5 | 9.17 | 14.19 | 25.01 | |||||||||||
| MEP | 0% | 17.76 | 40.38 | 82.98 | 203.57 | 0% | 10.96 | 17.76 | 32.05 | 113 | 0% | 87.08 | 189.47 | 345.21 | 1307.09 | ||||||
| OH-MiNP | 0% | 3.35 | 5.27 | 8.73 | 24.6 | 1.84% | 2.03 | 3.45 | 5.91 | 23.17 | |||||||||||
| oxo-MiNP | 0% | 1.39 | 2.17 | 3.66 | 9.65 | 3.07% | 1.19 | 2.08 | 3.62 | 14.93 | |||||||||||
| cx-MiNP | 0% | 2.88 | 4.55 | 7.5 | 19.5 | 0.61% | 3.85 | 6.11 | 9.91 | 45.64 | |||||||||||
| OH-MiDP | 0.78% | 0.75 | 1.19 | 2.06 | 5.9 | 1.84% | 1.23 | 1.76 | 2.83 | 5.11 | |||||||||||
| oxo-MiDP | 10.5% | 0.29 | 0.54 | 0.89 | 2.56 | 10.4% | 0.42 | 0.62 | 0.96 | 1.82 | |||||||||||
| cx-MiDP | 2.14% | 0.41 | 0.7 | 1.19 | 3.62 | 0.61% | 1.05 | 1.43 | 2.27 | 4.87 | |||||||||||
| MMP | 1.55% | 3.21 | 5.07 | 10.44 | 36.0 | 4.91% | 2.01 | 2.69 | 4.2 | 10.56 | |||||||||||
| PAHs | 1-OH-Pyr | 1.6% | 0.11 | 0.15 | 0.24 | 0.49 | 0% | 0.06 | 0.10 | 0.13 | 0.26 | 1.36% | 0.06 | 0.09 | 0.14 | 0.29 | |||||
| 4-OH-Phe | 20% | 0.02 | 0.05 | 0.12 | 1.5 | 0.39% | 0.02 | 0.04 | 0.08 | 0.26 | |||||||||||
| 1-OH-Phe | 5.5% | 0.08 | 0.17 | 0.34 | 0.70 | 0% | 0.08 | 0.12 | 0.2 | 0.46 | |||||||||||
| 2-OH-Flu | 0% | 0.21 | 0.36 | 0.56 | 1.0 | 10.5% | 0.23 | 0.43 | 0.69 | 2.19 | |||||||||||
| 2-OH-Nap | 0% | 3.0 | 5.2 | 7.1 | 21 | 0.19% | 1.86 | 3.15 | 5.89 | 15.9 | |||||||||||
| 1-OH-Nap | 0% | 1.0 | 1.7 | 3.3 | 6.2 | 3.5% | 0.36 | 0.68 | 1.41 | 4.88 | |||||||||||
| Bisphenols | BPA | 2.4% | 0.9 | 1.29 | 2.3 | 4.61 | 0% | 3.69% | 1.03 | 1.6 | 2.88 | 6.91 | |||||||||
| PFAS | PFNA | 0% | 0.23 | 0.3 | 0.36 | 0.49 | 0.61% | 0.7 | 0.95 | 1.39 | 2.14 | ||||||||||
| PFDA | 0% | 0.11 | 0.12 | 0.17 | 0.25 | 11.0% | 0.26 | 0.37 | 0.53 | 0.84 | |||||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodriguez Martin, L.; Ottenbros, I.; Vogel, N.; Kolossa-Gehring, M.; Schmidt, P.; Řiháčková, K.; Juliá Molina, M.; Varea-Jiménez, E.; Govarts, E.; Pedraza-Diaz, S.; et al. Identification of Real-Life Mixtures Using Human Biomonitoring Data: A Proof of Concept Study. Toxics 2023, 11, 204. https://doi.org/10.3390/toxics11030204
Rodriguez Martin L, Ottenbros I, Vogel N, Kolossa-Gehring M, Schmidt P, Řiháčková K, Juliá Molina M, Varea-Jiménez E, Govarts E, Pedraza-Diaz S, et al. Identification of Real-Life Mixtures Using Human Biomonitoring Data: A Proof of Concept Study. Toxics. 2023; 11(3):204. https://doi.org/10.3390/toxics11030204
Chicago/Turabian StyleRodriguez Martin, Laura, Ilse Ottenbros, Nina Vogel, Marike Kolossa-Gehring, Phillipp Schmidt, Katarína Řiháčková, Miguel Juliá Molina, Elena Varea-Jiménez, Eva Govarts, Susana Pedraza-Diaz, and et al. 2023. "Identification of Real-Life Mixtures Using Human Biomonitoring Data: A Proof of Concept Study" Toxics 11, no. 3: 204. https://doi.org/10.3390/toxics11030204
APA StyleRodriguez Martin, L., Ottenbros, I., Vogel, N., Kolossa-Gehring, M., Schmidt, P., Řiháčková, K., Juliá Molina, M., Varea-Jiménez, E., Govarts, E., Pedraza-Diaz, S., Lebret, E., Vlaanderen, J., & Luijten, M. (2023). Identification of Real-Life Mixtures Using Human Biomonitoring Data: A Proof of Concept Study. Toxics, 11(3), 204. https://doi.org/10.3390/toxics11030204